
800G Silicon Photonic Switches: Revolutionizing AIGC with Unprecedented Speed and Efficiency
In the ChatGPT boom, major global companies are actively embracing AIGC and releasing their own AI large-model products and applications. Public data shows that from GPT-1 to GPT-3, the number of model parameters has increased from 110 million to 175 billion. In order to prevent communication factors from becoming a shortcoming that restricts supercomputing, higher-speed network bandwidth and high-speed optical module transmission are required. Therefore, the ultra-high computing power support under large models may make 800G and 1.6T high-speed bandwidth the main demand for large-scale training in the future.
NVIDIA's latest H800 GPU card offers 3X the FP32 computing power of the previous A800 generation. H3C's R5500 G6 server can accommodate up to 8 GPU cards, achieving up to 32P FP8 computing power. The accompanying Cx7 network card supports 400Gb/s per port, with a maximum capacity of 2K ports for a single POD 400G network, covering around 256 servers. To meet future demands for large models, higher-speed bandwidth such as 800G and 1.6T will be crucial for supercomputing and large-scale training.
In actual operation, a 1% packet loss rate in Ethernet will result in a 50% performance loss in the computing cluster. For large models, AIGC applications, and other business applications that have strong requirements for cluster scale and performance, these performance losses are obviously unacceptable. The network needs to support the RDMA protocol to reduce transmission delays and improve network throughput.
In large-scale AI training clusters, designing an efficient networking solution for low-latency, high-throughput inter-machine communication is essential. This reduces data synchronization time between machines and increases the effective GPU computing time. Additionally, the high power consumption of extensive networking is a key factor to consider.
Currently, various ICT manufacturers are actively transitioning to 800G Ethernet around high-performance computing and AIGC products. H3C's 800G CPO silicon photonic data center switch, H3CS9827-64EO, has a single-chip 51.2T switching capacity, supports 64 800G ports, and integrates CPO silicon photonic technology, liquid cooling design, intelligent lossless and other advanced technologies to fully realize the three major requirements of high throughput, low latency and green energy saving of intelligent computing networks. It is suitable for business scenarios such as AIGC clusters or high-performance core switching of data centers, helping to release the ultimate computing power in the AIGC era.
The 800G product can support a single AIGC cluster with a scale of more than 32,000 nodes, which is a significant increase compared to the previous generation 400G networking scale. For example, if a large-scale training network with 8K GPU cards is planned, each card has one 400G port, and a total of 8K nodes need to be connected. In the case of a 1:1 convergence ratio, a 64-port 400G switch box is used for networking, a 2-level Spine-Leaf architecture, and a single POD supports up to 2K port access. At this time, a 3-level networking architecture is required to meet user needs; while using an 800G switch network, a single POD supports up to 8K 400G access under a 2-level Spine Leaf architecture, which can meet user needs. Therefore, on the basis of fully meeting the non-blocking transmission requirements of medium and large-scale AIGC clusters, 800G further increases the network scale of a single cluster, thereby maximizing the computing performance of the AIGC cluster.
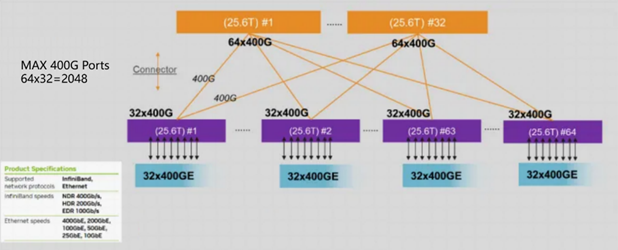
![]()

During parallel computing, different nodes in the AIGC cluster need to frequently synchronize model parameters. Once network latency occurs, it will have a serious impact on training efficiency and results, so there are extremely high requirements for network latency. The use of the new CPO silicon photonics technology unifies the NPU and TRX optoelectronic conversion modules responsible for data exchange, thereby reducing the circuit complexity, line latency, and transmission loss inside the switch, and achieving a 20% reduction in single-port transmission latency, which means that in a unit of time, the data interaction capability of the GPU in the AIGC cluster can be increased by 25%, greatly improving the GPU's computing efficiency.
At the same time, the continued rise of AIGC and large-scale computing power operation have made the "energy consumption anxiety" of data centers increasingly severe, and the construction of green data centers under high-speed interconnection has also become a future development trend.
All chip and module manufacturers are continuously making efforts in this field. Among them, the LPO (Linear Drive Pluggable Optical Module) technology represented by optical module manufacturers and the CPO (Chip Package Optimization) technology represented by chip manufacturers have outstanding advantages. Both technologies have the advantages of low latency, low power consumption and cost reduction. The difference is that LPO is the packaging form of optical modules and the technical route for the downward evolution of pluggable modules. It is mainly used to achieve power consumption reduction while reducing latency and cost; CPO is used to move optical modules close to the switch chip under the non-pluggable optical module architecture, package them together, and directly cross the data signal from the traditional PCB interconnection to the optical IO interconnection, which greatly reduces the power consumption of the chip to overcome the transmission impedance. With the "air cooling + liquid cooling" heat dissipation design, it can achieve a 30% reduction in TCO within a single cluster, effectively helping the construction of green data center networks.

The evolution of lossless technology in high-speed networks
In addition to significant requirements for cluster scale, bandwidth, latency, power consumption, etc., AIGC networks also have certain construction requirements for network stability and automation. The construction of intelligent lossless networks is often based on the RDMA protocol and congestion control mechanism. After RDMA is enabled, mutual access between GPUs (GDR, GPU Direct RDMA) or GPU access to storage (GDS, GPU Direct Storage) bypasses the memory and CPU, reducing transmission latency and releasing computing power.
For AIGC scenarios, H3C released the 800G CPO switch S9827-64EO, which naturally supports lossless related functions, such as PFC, ECN, AI ECN, iNOF (Intelligent Lossless NVMe Over Fabric), IPCC (Intelligent Proactive Congestion Control), etc. At the same time, based on traditional RoCE , it conducted research and exploration on the two technologies of traffic identification and detection and dynamic load balancing, and launched the SprayLink and AgileBuffer functions.
SprayLink has achieved innovations in congestion prevention and load balancing technologies. By real-time monitoring of bandwidth utilization, egress queues, cache occupancy, transmission delay and other refined data of each physical link in LACP/ECMP, it can dynamically share the load of the elephant flow based on the Per-Packet method, that is, each data packet is allocated to the link with the best resources at the time, rather than according to a fixed hash algorithm. Based on this method, the bandwidth utilization of the link can be increased to more than 95%. By improving bandwidth utilization, the end-to-end transmission delay of the elephant flow in the network is reduced, and the efficiency of AI training is improved.
Finally, in response to switching changes in network topology, the S9827 silicon optical switch supports ns-level hardware automatic perception capabilities, can quickly identify link switching actions, and complete a series of actions such as corresponding table refresh, protocol docking, and lossless parameter adjustment, achieving automatic perception and self-adjustment effects, greatly reducing the impact of network failures on services, and strongly supporting the stable operation of the AIGC intelligent computing cluster. It helps AIGC networks achieve a new intelligent lossless experience with high throughput, zero packet loss, and low latency.

Intelligent Computing | The DeepSeek Catalyst: Competing in the Age of AI Inference

REDnote Partners With H3C to Deploy the First DDC Architecture AI Computing Network Cluster Globally

In-Depth Analysis of H3C's Next-Generation Lossless Network Solution Based on DDC Architecture

