- Products and Solutions
- Industry Solutions
- Services
- Support
- Training & Certification
- Partners
- About Us
- Contact Sales
- Become a Partner
-
 Login
Login
Country / Region
Internet Smart Computing Solution
The first things that come to mind when talking about a server are "three basic components", namely CPU, memory, and hard disk. In addition to them, network adapter also plays an indispensable role in a server as it has the two functions below:
First, it encapsulates the data of the server into frames, and sends the data to the network through network cables.
Second, it receives frames from other devices on the network, reassembles the frames into data, and sends the data to the server.
The most important parameter of a network adapter is bandwidth, which indicates the overall processing capacity of the server network. With increasing demand for cloud computing, big data processing, and high-speed storage, network bandwidth develops quickly. Cloud customers are increasingly concerned about the network speed and network bandwidth. As services exert a great impact on the traffic of a data center, companies need a large number of servers with high bandwidth to form a cluster system to work together. It takes ten years for a network adapter to evolve from 1G to 10G, and now many IDCs are using gigabit networks in equipment rooms. However, it takes less than three years to make a 25G network adapter popular. The leading Internet companies have basically switched to 25G networks and have started deploying 50G and 100G networks.
As the network adapter grows faster, higher requirements have been posed for latency. Under such situation, the traditional x86 server can no longer meet the requirements of existing services. Therefore, the software-based solution DPDK has emerged, which employs polling method and processes data packets in user mode, hence significantly improving the server network performance. The advantage of DPDK is low investment with good profits. With only the traditional network adapter and software kit, performance can be improved. The disadvantage is that it requires a dedicated CPU to process data packets. However, with the introduction of overlay protocols, such as VXLAN and virtual switching technologies, such as OpenFlow and Open vSwitch (OVS), the complexity of server-based network data plane increases rapidly, the fixed traffic processing capacity of traditional network adapters makes them unable to adapt to SDN and NFV. Moreover, the increased network interface bandwidth could lead to high CPU usage, which is contrary to the concept of cloud computing, so SmartNICs emerge at this moment.
Different from the traditional network adapters, SmartNICs feature high performance and programmability at the same time. They can not only process the high-speed network data flow, but also program the network adapters for the customized processing logic.
Three forms of SmartNICs
Currently, SmartNICs come in the following three forms:
1. Multi-core SmartNIC based on the Application Specific Integrated Circuit (ASIC) with multiple CPU cores
2. SmartNIC based on the field programmable gate array (FPGA)
3. System-on-a-chip (SOC), combining the hardware FPGA with ASIC network controller
Different implementations have both advantages and disadvantages in terms of cost, programmability, and flexibility. The ASICs are affordable, but with limited flexibility. Although the ASIC-based NICs are relatively easy to configure, their capabilities are restricted by those ASIC defined functions, and some complex loads may not be supported. In contrast, the FPGA-based NIC is highly programmable, and can work with almost any function effectively. But the FPGA is difficult to program and costly, which is not popular among small customers. Therefore, when it comes to complex cases, SOC is a preferred choice for SmartNIC, as it is affordable, effective, programmable, and flexible.
Specifically, SmartNICs bring the following benefits to a data center network:
1. Network acceleration, storage, and computing tasks are directly executed on NICs, so there is no need to run these loads on a server. This frees up CPU cycles, significantly improves server performance, and reduces overall power consumption, resulting in lower total cost of ownership.
2. The increasingly complex network tasks, including VxLAN and OVS, are offloaded. Server processors can perform actual revenue-generating tasks.
3. The offloaded functions are executed by faster hardware rather than slower software, increasing effective network bandwidth and throughput. Moreover, additional and flexible functions are provided to adapt to changing network and storage protocols.
In fact, SmartNICs have been used by large Internet companies and leading CSPs. The core idea is to offload service loads to special-purpose hardware. For example, Microsoft uses the FPGA on Azure for CPU offloading and network acceleration. AWS even developed a Nitro architecture to offload services such as VPC, EBS, and storage to hardware. Chinese company Alibaba's X-Dragon architecture follows similar ideas. The core of its architecture is a MOC card, on which the entire hypervisor runs. In this way, the CPU and memory of the server can be completely released for customers.
H3C's newly released UIS 7.0 Chixiao acceleration architecture is an industry-leading hyper-converged architecture that enables intelligent acceleration in both frontend and backend at the same time. With the intelligent acceleration card, the Chixiao acceleration engine provides frontend-to-backend acceleration with no host-side loss, allowing for creating over 50% more VMs with the same number of CPU cores, reducing per-VM cost by over 30% and improving IOPS performance by over 10 times, when compared with a non-acceleration solution. A lossless network with the shortest IO path in the industry reduces network latency from milliseconds to nanoseconds. The Chixiao acceleration architecture is compatible with virtualization, bare metal, container, and function computing.
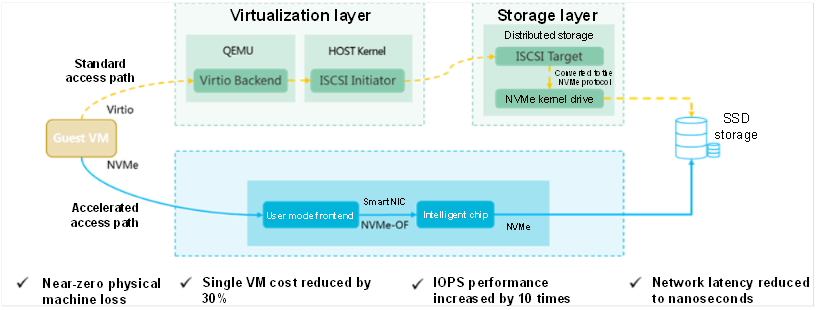
H3C hyper-converged architecture UIS uses SmartNICs in the latest version 7.0 to offload storage and network processing to the intelligent acceleration card. In this way, almost all the CPUs can be used for computing, greatly improving the computing power. Compared with the current hyper-converged solution, it has higher performance and lower TCO.
