- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们




2022 年,OpenAI开发的ChatGPT 爆火出圈,掀起新一轮AIGC(Artificial Intelligence Generated Content,人工智能生成内容)浪潮,开启AI新纪元。
据分析公司SimilarWeb数据显示,自去年11月底ChatGPT的网站上线后,全球访问量搜索引擎持续领跑 ,已经超过了必应、DuckDuckGo等其他国际搜索引擎。
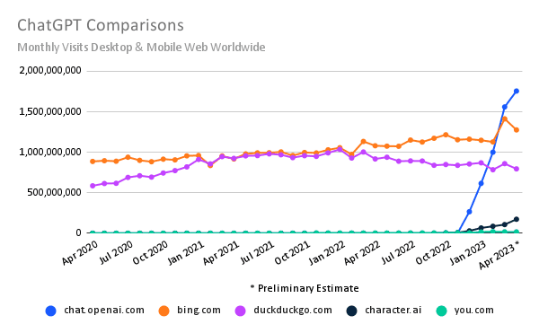
图1SimilarWeb数据
在ChatGPT热潮里,全球各大巨头企业都在积极拥抱AIGC,发布自己的AI 大模型产品和应用。截止到今年的7月初,至少5家上市公司相继举办AI产品发布会。如百度的“文心”大模型、腾讯的“混元”大模型、谷歌的“LaMDA”大模型、阿里的“通义千问”,火山引擎的“火山方舟”、以及京东即将发布的“言犀大模型”等。
当下带宽速率带来的规模限制与挑战
公开数据显示,从GPT-1到GPT-3,模型的参数量从1.1亿个增长到了1750亿个。有传言称,GPT-4模型的参数达到5000亿个,甚至可能超过万亿规模。因此智算中心的建设,GPU已经成为大模型训练的核心算力支柱。
NVIDIA最新发布的H800 GPU卡,浮点算力(FP32)较上一代A800提升3X,新华三的R5500 G6服务器最大可支持8卡GPU,单机高达32P FP8算力。其配套的Cx7高速网卡也支持到单端口400Gb/s。按照单POD 400G 的Spine-Leaf 2级组网架构1:1收敛计算,最大支持2K的端口接入能力,约256台服务器规模,无法满足未来大模型的组网需求。为避免通信因素成为制约超算的短板,则需要更高速率的网络带宽及高速光模块传输。因此,大模型下的超高算力支撑,或使未来800G、1.6T 高速率带宽或将成为大规模训练的主力需求。
而在实际运行中,以太网中1%的丢包率就会导致计算集群50%的性能损失;而对于大模型、AIGC应用等,对集群规模和性能有着强需求的业务应用而言,这些性能损失显然是无法接受的。需要网络支持RDMA协议,减少传输时延,提升网络吞吐。
因此,在 AI 大模型的大规模训练集群中,如何设计高效的集群组网方案,满足低时延、高吞吐的机间通信,从而降低多机多卡间数据同步的通信耗时,提升 GPU 有效计算时间占比(GPU 计算时间/整体训练时间),对于 AI 分布式训练集群的效率提升至关重要。而大规模组网带来的高功耗,也是不容忽视的。
800G发布 突破AIGC大规模组网限制
当前各通信厂商,正在围绕着高性能计算及AIGC等产品积极向800G以太网过渡。其中新华三集团在2023年领航者峰会,全球首发800G CPO硅光数据中心交换机,H3CS9827-64EO,单芯片51.2T交换能力,支持64个800G端口,并融合CPO硅光技术、液冷散热设计、智能无损等先进技术,全面实现智算网络高吞吐、低时延、绿色节能三大需求,适用于AIGC集群或数据中心高性能核心交换等业务场景中,助力AIGC时代极致算力释放。

图2 H3C S9827-64EO
该800G 产品的发布,可支撑单个AIGC集群规模突破3.2万台节点,较上一代400G组网规模大幅提升。比如:规划一张8K个GPU卡的大规模训练网络,每张卡1个400G端口,共计需要8K个节点接入。在1:1收敛比的情况下,使用64口400G交换机盒盒组网,2级Spine-Leaf架构,单POD最多支持2K的端口接入,此时需要使用3级组网架构才可满足用户需求;而使用800G交换机组网,2级Spine Leaf架构下,单POD最多支持8K的400G接入,即可满足用户需求。因此,800G在完全满足中大规模AIGC集群无阻塞传输需求的基础上,进一步提升单集群的网络规模,从而最大程度保障AIGC集群的运算效能。
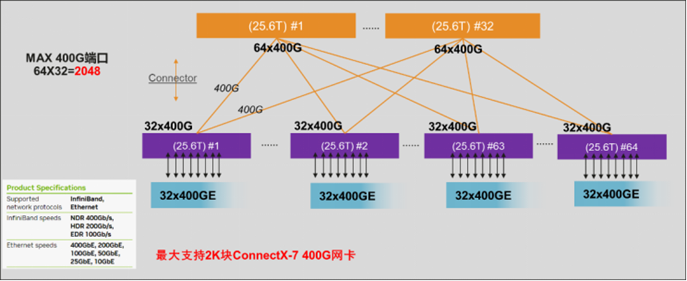
图3 单POD 400G组网最大规模

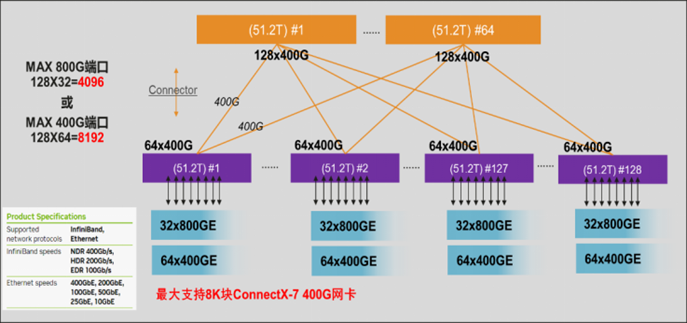
图4 单POD 800G组网最大规模
性能飞涨与低碳环保之间的平衡
在并行运算过程中,AIGC集群的不同节点之间需频繁地同步模型参数,一旦出现网络延迟问题,将会对训练效率和结果产生严重影响,因此对于网络时延有着极高要求。全新CPO硅光技术的使用,将负责数据交换的NPU与TRX光电转换模块进行统一封装,以此减少交换机内部的电路复杂度、线路延迟、传输损耗,实现了单端口传输时延度降低20%,意味着在单位时间内,AIGC集群中GPU的数据交互能力可以提升25%,大大提升GPU的运算效率。
同时,AIGC的持续升温和大规模的算力运行,使得数据中心的“能耗焦虑”日益加剧,高速互联下的绿色数据中心的建设也成为了未来的发展趋势。
各芯片和模块厂商均在该领域持续发力中,其中以光模块的厂商为代表的LPO(线性驱动可插拨光模块)技术和芯片厂商为代表的CPO(芯片封装优化)技术凸显优势。两种技术均具备低时延、低功耗、降成本的优势。区别在于LPO是光模块的封装形式,是可插拔模块向下演进的技术路线,主要用来实现降功耗,同时降低时延和成本;CPO则是用于在不可插拔光模块架构下,把光模块移到靠近交换机芯片,封装在一起,将数据信号从传统的PCB互联直接跨越到光IO互联,极大降低了芯片用于克服传输阻抗所付出的功耗,搭配“风冷+液冷”的散热设计,可实现单集群内的TCO降低30%,有效助力绿色数据中心网络建设。

高速网络中的无损技术再演进
AIGC网络除了对集群规模、带宽、时延、功耗等有显著要求外,网络稳定性及自动化也存在一定的建设需求。智能无损网络的构建往往基于RDMA协议及拥塞控制机制,开启RDMA后,GPU之间(GDR,GPU Direct RDMA)互访或GPU访问存储(GDS,GPU Direct Storage)均绕过了内存和CPU,降低传输时延,释放算力。
针对AIGC场景,H3C发布的800G CPO交换机 S9827-64EO,天然支持无损相关功能,如:PFC、ECN、AI ECN、iNOF(Intelligent Lossless NVMe Over Fabric,智能无损存储网络)、IPCC(Intelligent Proactive Congestion Control,智能主动拥塞控制)等功能,同时,在传统RoCE基础上,分别在流量识别与探测、动态负载均衡两个技术上进行了研究探索,推出了SprayLink和AgileBuffer功能。
SprayLink在拥塞预防和负载均衡技术上实现了创新,通过实时监控LACP/ECMP中各物理链路的带宽利用率、出口队列、缓存占用、传输时延等精细化数据,对大象流做到基于Per-Packet方式的动态负载分担,也就是将每个数据包分配到当时资源最优的链路上,而非按照固定哈希算法分配。基于此方式可以使链路的带宽利用率提高到95%以上。通过带宽利用率的提升,减少了大象流在网络中端到端传输的时延,提升了AI训练效率。
在提升大象流传输效率的同时,结合AgileBuffer技术,也可以减少小速率流量(老鼠流)的丢包概率。AgileBuffer通过定期检测老鼠流队列对Buffer的占用比例及丢包情况,自动调整Buffer空间和丢弃概率,最大程度优化大象流对老鼠流的影响,实现多业务均衡稳定运行。
最后,在应对网络拓扑变化的切换响应上,S9827硅光交换机支持ns级硬件自动感知能力,能够快速识别链路切换动作,并完成相应的表项刷新,协议对接、无损参数调整等一系列动作,实现自动感知、自我调节效果,极大降低了网络故障对业务的影响程度,有力支撑AIGC智算集群稳定运行。助力AIGC网络的高吞吐、零丢包、低时延的智能无损新体验。
结语
AIGC产业的爆发及强算力带动了800G以太网的需求。新华三集团深耕网络二十余载,致力于先进网络技术的探索和创新, 800G CPO硅光数据中心交换机的首发、助力数据中心网络变革,全面拥抱AIGC时代。未来,新华三将秉持“精耕务实,为时代赋智慧”的理念,持续提升云智原生数字平台的能力,为数字经济高质量发展夯实智能联接基石。
注:参考以下文献
中国移动研究院技术白皮书—《面向 AI 大模型的智算中心 网络演进白皮书》(2023年)
知乎—《AIGC引爆800G以太网需求,如何通过IP和验证赋能以太网?》
新华三公众号—《全球首发!新华三推出800G CPO硅光数据中心交换机》










