- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们




IPv6技术白皮书
Copyright © 2022 新华三技术有限公司 版权所有,保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传播。
除新华三技术有限公司的商标外,本手册中出现的其它公司的商标、产品标识及商品名称,由各自权利人拥有。
本文中的内容为通用性技术信息,某些信息可能不适用于您所购买的产品。
IPv6(Internet Protocol Version 6,互联网协议版本6)是网络层协议的第二代标准协议,也被称为IPng(IP Next Generation,下一代互联网协议)。IPv6不仅解决了IPv4地址空间不足的问题,还在IPv4协议的基础上进行了一些改进,例如,通过扩展头提高IPv6协议的可扩展性、内置安全性解决网络安全问题。
IPv6可以为互联网和物联网提供更加广泛的连接,实现万物互联,打造数字化基础设施,促进物联网、工业互联网、人工智能等新应用、新领域的创新。在5G、物联网等新兴领域飞速发展的今天,IPv6协议的魅力不断展现,IPv6协议获得了更加广阔的发展空间。
本文在讲解IPv6技术的优势、基于IPv6的应用协议扩展后,将介绍IPv6协议的发展方向(即IPv6+),并提供几种常见的IPv6部署方案,以帮助用户理解和部署IPv6协议。
IPv6地址的长度是128比特(16字节),可以提供超过3.4×1038个地址。在万物互联的需求下,IPv6具有足够大的地址空间,可以为每一个具有联网需求的终端提供IPv6地址,而不用担心地址耗尽,极大地增强了互联网的服务能力。
IPv6的地址空间采用了层次化的地址结构,地址管理更加便捷,且有利于路由快速查找,借助路由聚合,还可以有效减少IPv6路由表占用的系统资源。
IPv6地址使用多层等级结构。地址注册机构分配IPv6地址范围后,服务提供商、组织机构可以根据各自的需要在该IPv6地址范围内分层级、更加精细地划分地址范围,以管理所辖范围内的地址分布。如图1所示,IPv6地址由以下几部分组成:
· 网络前缀:由CNNIC(China Internet Network Information Center,中国互联网络信息中心)和ISP分配。
· 子网ID:组织机构根据需要分层级划分地址范围。例如,先根据地域分别为省、市分配地址范围,再按照业务类型分配地址范围。
· 接口ID:网络中主机的标识。
图1 IPv6地址结构

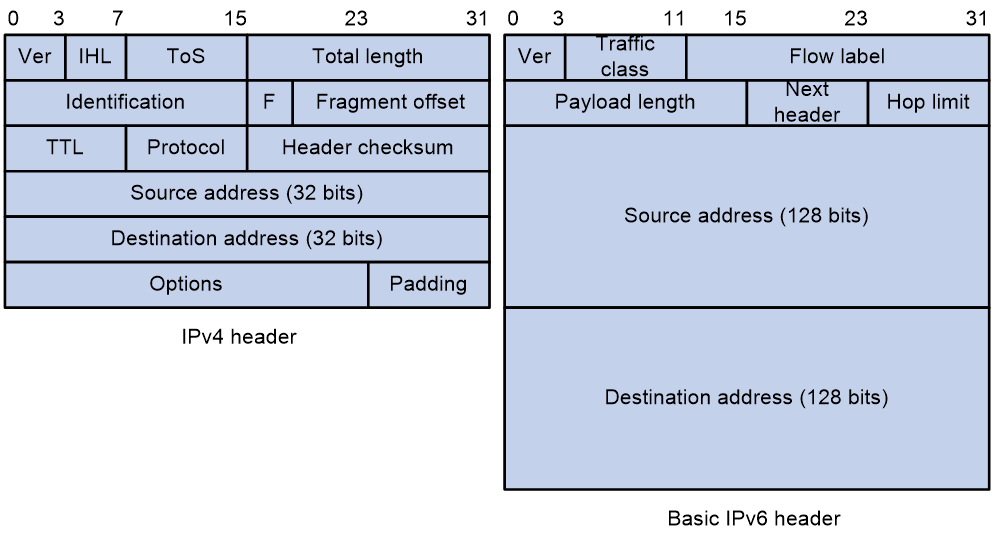
通过将IPv4报文头中的某些字段裁减或移入到扩展报文头,减小了IPv6基本报文头的长度。IPv6使用固定长度的基本报文头,从而简化了转发设备对IPv6报文的处理,提高了转发效率。尽管IPv6地址长度是IPv4地址长度的四倍,但IPv6基本报文头的长度只有40字节,为IPv4报文头长度(不包括选项字段)的两倍。
图2 IPv4报文头和IPv6基本报文头格式比较
IPv6取消了IPv4报文头中的选项字段,并引入了多种扩展报文头,在提高处理效率的同时还大大增强了IPv6的灵活性,为IP协议提供了良好的扩展能力。IPv4报文头中的选项字段最多只有40字节,而IPv6扩展报文头的大小只受到IPv6报文大小的限制。
IPv6支持的扩展头如表1所示。扩展头使得IPv6协议具有良好的扩展性。根据业务需要,IPv6不仅可以定义新的扩展头,还可以在已有扩展头中定义新的子扩展头。
表1 IPv6扩展头
|
扩展头名称 |
类型值 |
处理节点 |
用途 |
|
逐跳选项头(Hop-by-Hop Options Header) |
0 |
报文转发路径上的所有节点 |
用于巨型载荷告警、路由器告警、预留资源(RSVP) |
|
路由头(Routing Header) |
43 |
目的节点及报文必须经过的中间节点 |
用来指定报文必须经过的中间节点 |
|
分段头(Fragment Header) |
44 |
目的节点 |
当IPv6报文的长度超过报文经过路径的PMTU(Path MTU,路径MTU)时,源节点将通过分段头对该IPv6报文进行分片 在IPv6中,仅源节点可以对报文进行分片,中间节点不可以对报文进行分片
PMTU是从源节点到目的节点的报文转发路径上最小的MTU |
|
封装安全载荷头(Encapsulating Security Payload Header,ESP Header) |
50 |
目的节点 |
用来提供数据加密、数据来源认证、数据完整性校验和抗重放功能 |
|
认证头(Authentication Header) |
51 |
目的节点 |
用来提供数据来源认证、数据完整性校验和抗重放功能,它能保护报文免受篡改,但不能防止报文被窃听,适合用于传输非机密数据 AH提供的认证服务要强于ESP |
|
目的选项头(Destination Options Header) |
60 |
目的节点、路由头中指定的中间节点 |
用来携带传递给目的节点、路由头中指定中间节点的信息。例如,移动IPv6中,目的选项头可以用于在移动节点和家乡代理之间交互注册信息 |
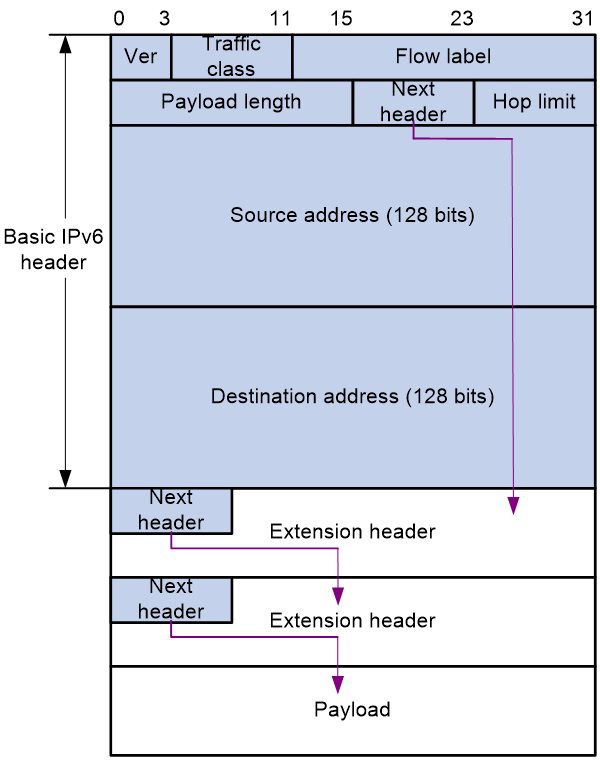
一个IPv6报文可以携带0个、1个或多个扩展头。如图3所示,IPv6通过Next header字段标明下一个扩展头的类型。例如,IPv6基本报文头中的Next header字段取值为43时,表示紧跟在IPv6基本报文头后的扩展头为路由头;路由头中的Next header字段取值为44时,表示路由头后的扩展头为分段头。
![]()
最后一个扩展头的Next header字段用来标识Payload类型。例如,取值为6,表示Payload为TCP报文;取值为17,表示Payload为UDP报文。
图3 IPv6扩展头的报文格式
IPv6的邻居发现协议是通过一组ICMPv6(Internet Control Message Protocol for IPv6,IPv6互联网控制消息协议)消息实现的,管理着邻居节点间(即同一链路上的节点)信息的交互。它代替了ARP(Address Resolution Protocol,地址解析协议)、ICMPv4路由器发现和ICMPv4重定向消息,并提供了一系列其他功能:
· 地址解析:获取同一链路上邻居节点的链路层地址,功能与IPv4的ARP相同。
· 邻居可达性检测:在获取到邻居节点的链路层地址后,检测邻居节点的状态,验证邻居节点是否可达。
· 重复地址检测:当节点获取到一个IPv6地址后,验证该地址是否已被其他节点使用,与IPv4的免费ARP功能相似。
· 路由器发现/前缀发现:节点获取邻居路由器的信息、所在网络的前缀、以及其他配置参数。节点获取到所在网络前缀后,可以根据该前缀自动生成IPv6地址,该过程称为IPv6地址无状态自动配置。
· 重定向功能:当网络中存在更优的路径时,路由器向主机发送ICMPv6重定向报文,通知主机选择更好的下一跳进行后续报文的发送。该功能与IPv4的ICMP重定向消息的功能相同。
IPv4协议本身未提供加密、认证等安全功能,需要与其他安全协议(如IPsec)配合使用,或由应用协议来提供安全性,增加了应用协议设计的复杂度。IPv6协议在设计时便充分考虑了安全问题,在IPv6协议中定义了ESP头和认证头,通过ESP头和认证头为报文传输提供端到端的安全性。基于IPv6协议的应用可以直接继承IPv6协议的安全功能,为解决网络安全问题提供了标准,并提高了不同IPv6应用之间的互操作性。
用于设备管理的协议(Telnet、SSH、SNMP等)、高可靠性机制(VRRP、M-LAG等)、安全协议(802.1X、端口安全等)无需改动或稍做修改即可支持IPv6。但是,还有一些IPv4网络中运行的应用层协议、路由协议、组播协议、安全协议等,为了适应IPv6协议,需要进行一些扩展。本节介绍这些协议在IPv6网络中的扩展方式。
节点可以通过如下方式获取IPv6全球单播地址:
· 手工配置:用户手工为节点上的接口指定IPv6单播地址。
· 无状态地址自动配置:节点通过邻居发现协议获取到网络前缀后,根据该前缀自动生成IPv6单播地址。
· 有状态地址自动配置:节点通过DHCPv6协议从DHCPv6服务器获取IPv6单播地址。
不同IPv6全球单播地址配置方式的适用场景如表2所示。
表2 不同IPv6全球单播地址配置方式的适用场景
|
地址配置方式 |
优缺点 |
适用场景 |
前缀长度要求 |
|
手工配置 |
优点:无需协议报文交互 缺点:手工配置工作量,且无法动态调整 |
链路本地地址或Loopback接口地址 |
无要求,可自定义 |
|
无状态地址自动配置 |
优点:无需额外部署服务器,实现较为简单 缺点:无法精确控制为节点分配的IPv6地址 |
对终端访问行为无强管控需求。例如物联网终端(视频监控、路灯等) |
固定为64位 |
|
有状态地址自动配置 |
优点:可以精确控制分配给节点的IPv6地址,并记录地址分配信息 缺点:需要在网络中部署DHCPv6服务器,实现较为复杂 |
对终端访问行为有强管控需求。例如校园网、办公区等 |
无要求,可自定义 |
无状态地址自动配置和有状态地址自动配置可以配合使用。例如,通过无状态地址自动配置获取IPv6地址后,使用有状态地址自动配置获取其他网络配置参数(如DNS服务器地址等)。
无状态地址自动配置通过IPv6的邻居发现协议实现,其工作过程为:
(1) 路由器通过以下两种方式通告前缀信息:
¡ 路由器周期性地向所有节点的多播地址(FF02::1)发送RA(Router Advertisement)消息,其中包括IPv6前缀、前缀的生命期、跳数限制等信息。
¡ 节点启动时,向所有路由器的多播地址(FF02::2)发送RS(Router Solicitation)消息,路由器接收到RS消息后,向所有节点的多播地址(FF02::1)应答RA消息。
![]()
前缀的生命期包括如下两种:
· 有效生命期:表示前缀有效期。在有效生命期内,通过该前缀自动生成的地址可以正常使用;有效生命期过期后,通过该前缀自动生成的地址变为无效,将被删除。
· 首选生命期:表示首选通过该前缀无状态自动配置地址的时间。首选生命期过期后,节点通过该前缀自动配置的地址将被废止。节点不能使用被废止的地址建立新的连接,但是仍可以接收目的地址为被废止地址的报文。首选生命期必须小于或等于有效生命期。
(2) 节点将路由器返回的RA消息中的地址前缀与本地的接口ID组合,生成IPv6单播地址。节点还会根据RA消息返回的配置信息自动配置节点,例如将RA消息中的跳数限制设置为本地发送的IPv6报文的最大跳数。
(3) 节点对生成的IPv6单播地址进行重复地址检测。检测方法为:节点在本地链路上,发送NS(Neighbor Solicitation,邻居请求)消息,NS消息的目的地址为根据前缀自动生成的IPv6单播地址的被请求节点多播地址。如果节点没有接收到NA(Neighbor Advertisement,邻居通告)消息,则认为该地址不存在冲突,可以使用;否则,认为该地址存在冲突,不会使用该地址。
![]()
被请求节点(Solicited-Node)多播地址主要用于获取同一链路上邻居节点的链路层地址及实现重复地址检测。每一个单播或任播IPv6地址都有一个对应的被请求节点地址。其格式为:
FF02:0:0:0:0:1:FFXX:XXXX
其中,FF02:0:0:0:0:1:FF为104位固定格式;XX:XXXX为单播或任播IPv6地址的后24位。
节点自动根据本地信息生成借口ID,不同接口的IEEE EUI-64格式接口ID的生成方法不同:
· 所有IEEE 802接口类型(例如,以太网接口、VLAN接口):IEEE EUI-64格式的接口ID是从接口的链路层地址(MAC地址)变化而来的。IPv6地址中的接口ID是64位,而MAC地址是48位,因此需要在MAC地址的中间位置(从高位开始的第24位后)插入十六进制数FFFE(1111111111111110)。为了使接口ID的作用范围与原MAC地址一致,还要将Universal/Local (U/L)位(从高位开始的第7位)进行取反操作。最后得到的这组数就作为EUI-64格式的接口ID。
图4 MAC地址到EUI-64格式接口ID的转换过程

· Tunnel接口:IEEE EUI-64格式的接口ID的低32位为Tunnel接口的源IPv4地址,ISATAP隧道的接口ID的高32位为0000:5EFE,其他隧道的接口ID的高32位为全0。
· 其他接口类型(例如,Serial接口):IEEE EUI-64格式的接口ID由设备随机生成。
接口根据无状态地址自动配置自动生成IPv6全球单播地址时,如果接口是IEEE 802类型的接口(例如,以太网接口、VLAN接口),其接口ID是由MAC地址根据一定的规则生成,此接口ID具有全球唯一性。对于不同的前缀,接口ID部分始终不变,攻击者通过接口ID可以很方便地识别出通信流量是由哪台设备产生的,并分析其规律,会造成一定的安全隐患。
在无状态地址自动配置时,如果自动生成接口ID不断变化的IPv6地址,则可以加大攻击的难度,从而保护网络。为此,设备提供了临时地址功能,进行无状态地址自动配置,IEEE 802类型的接口可以同时生成两类地址:
· 公共地址:地址前缀采用RA报文携带的前缀,接口ID由MAC地址产生。接口ID始终不变。
· 临时地址:地址前缀采用RA报文携带的前缀,接口ID由系统根据MD5算法计算产生。接口ID不断变化。
指定优先选择临时地址后,系统将优先选择临时地址作为报文的源地址。当临时地址的有效生命期过期后,这个临时地址将被删除,同时,系统会通过MD5算法重新生成一个接口ID不同的临时地址。所以,该接口发送报文的源地址的接口ID总是在不停变化。如果生成的临时地址因为DAD冲突不可用,就采用公共地址作为报文的源地址。
当用户需要切换到新的网络前缀时,利用无状态地址自动配置可以方便、透明地实现前缀重新编址。前缀重新编址的过程为:
(1) 路由器在本地链路上通过RA消息发布旧的IPv6前缀,将该前缀的有效生命期和首选生命期降低到接近于0的值。
(2) 路由器在本地链路上通过RA消息发布新的IPv6前缀。
(3) 节点上同时存在新旧两个前缀生成的两个IPv6地址——新IPv6地址和旧IPv6地址。使用旧IPv6地址的连接仍然可以被处理,新建立的连接使用新IPv6地址。当旧IPv6地址的有效生命期结束后,该地址不再使用,节点仅使用新IPv6地址通信。
DHCPv6(Dynamic Host Configuration Protocol for IPv6,支持IPv6的动态主机配置协议)针对IPv6编址方案设计,用来为主机分配IPv6前缀、IPv6地址和其他网络配置参数。
与其他IPv6地址分配方式(手工配置、无状态地址自动配置)相比,DHCPv6具有以下优点:
· 更好地控制地址的分配。通过DHCPv6不仅可以记录为主机分配的地址,还可以为特定主机分配特定的地址,以便于网络管理。
· 为DHCPv6客户端分配前缀,DHCPv6客户端再作为路由器将前缀通告给主机,以便于主机无状态自动配置IPv6地址。通过这种方式,可以减少DHCPv6服务器管理的IPv6地址数量,并实现全网络的自动配置和管理。
· 除了IPv6前缀、IPv6地址外,还可以为主机分配DNS服务器、域名后缀等网络配置参数。
DHCPv6服务器为客户端分配地址/前缀的过程分为两类:
· 交互两个消息的快速分配过程
图5 地址/前缀快速分配过程

如图5所示,地址/前缀快速分配过程为:
a. DHCPv6客户端在向DHCPv6服务器发送的Solicit消息中携带Rapid Commit选项,标识客户端希望服务器能够快速为其分配地址/前缀和其他网络配置参数。
b. 如果DHCPv6服务器支持快速分配过程,则直接返回Reply消息,为客户端分配IPv6地址/前缀和其他网络配置参数。如果DHCPv6服务器不支持快速分配过程,则采用交互四个消息的分配过程为客户端分配IPv6地址/前缀和其他网络配置参数。
· 交互四个消息的分配过程
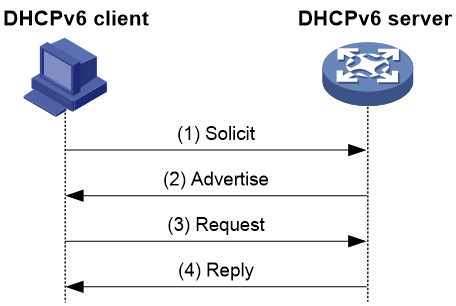
交互四个消息分配过程的简述如表3。
|
步骤 |
发送的消息 |
说明 |
|
(1) |
Solicit |
DHCPv6客户端发送该消息,请求DHCPv6服务器为其分配IPv6地址/前缀和网络配置参数 |
|
(2) |
Advertise |
如果Solicit消息中没有携带Rapid Commit选项,或Solicit消息中携带Rapid Commit选项,但服务器不支持快速分配过程,则DHCPv6服务器回复该消息,通知客户端可以为其分配的地址/前缀和网络配置参数 |
|
(3) |
Request |
如果DHCPv6客户端接收到多个服务器回复的Advertise消息,则根据消息接收的先后顺序、服务器优先级等,选择其中一台服务器,并向该服务器发送Request消息,请求服务器确认为其分配地址/前缀和网络配置参数 |
|
(4) |
Reply |
DHCPv6服务器回复该消息,确认将地址/前缀和网络配置参数分配给客户端使用 |
DHCPv6服务器分配给客户端的IPv6地址/前缀具有一定的租借期限,该租借期限称为租约。租借期限由有效生命期决定。地址/前缀的租借时间到达有效生命期后,DHCPv6客户端不能再使用该地址/前缀。在有效生命期到达之前,如果DHCPv6客户端希望继续使用该地址/前缀,则需要申请延长地址/前缀租约。
图7 通过Renew更新地址/前缀租约

如图7所示,地址/前缀租借时间到达时间T1(推荐值为首选生命期的一半)时,DHCPv6客户端会向为它分配地址/前缀的DHCPv6服务器发送Renew报文,以进行地址/前缀租约的更新。如果客户端可以继续使用该地址/前缀,则DHCPv6服务器回应续约成功的Reply报文,通知DHCPv6客户端已经成功更新地址/前缀租约;如果该地址/前缀不可以再分配给该客户端,则DHCPv6服务器回应续约失败的Reply报文,通知客户端不能获得新的租约。
图8 通过Rebind更新地址/前缀租约
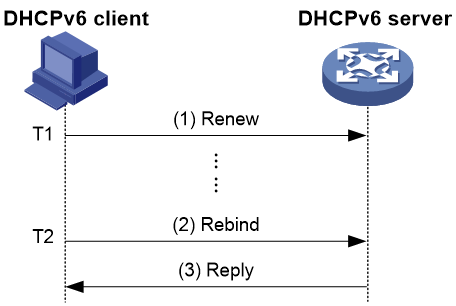
如图8所示,如果在T1时发送Renew请求更新租约,但是未收到DHCPv6服务器的回应报文,则DHCPv6客户端会在T2(推荐值为首选生命期的0.8倍)时,向所有DHCPv6服务器组播发送Rebind报文请求更新租约。如果客户端可以继续使用该地址/前缀,则DHCPv6服务器回应续约成功的Reply报文,通知DHCPv6客户端已经成功更新地址/前缀租约;如果该地址/前缀不可以再分配给该客户端,则DHCPv6服务器回应续约失败的Reply报文,通知客户端不能获得新的租约;如果DHCPv6客户端未收到服务器的应答报文,则到达有效生命期后,客户端停止使用该地址/前缀。
Option 17称为厂商自定义选项(Vendor-specific Information),是RFC中规定的保留选项,
设备作为DHCPv6服务器时,可以利用该选项携带额外的网络参数(例如TFTP服务器名称、地址或设备的配置文件名等)并发送给DHCPv6客户端,以便为DHCPv6客户端提供相应的服务。
为了提供可扩展性,通过Option 17为客户端分配更多的信息,Option 17采用子选项的形式,通过不同的子选项为用户分配不同的网络配置参数,目前每个厂商自定义选项下最多配置16个子选项内容。
· Option 18
Option 18称为接口ID选项(Interface ID),设备接收到DHCPv6客户端发送的DHCPv6请求报文后,在该报文中添加Option 18选项(DHCPv6中继会在Relay-forwad报文中添加Option 18选项),并转发给DHCPv6服务器。服务器可根据Option 18选项中的客户端信息选择合适的地址池为DHCPv6客户端分配IPv6地址。图9为Option 18选项格式。
图9 Option 18选项格式
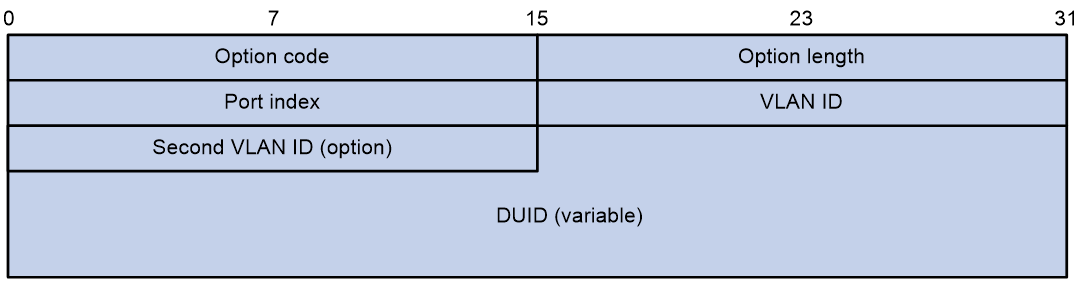
各字段的解释如下:
¡ Option code:Option编号,取值为18。
¡ Option length:Option字段长度。
¡ Port index:DHCPv6设备收到客户端请求报文的端口索引。
¡ VLAN ID:第一层VLAN信息。
¡ Second VLAN ID:第二层VLAN信息。选项格式中的Second VLAN ID字段为可选,如果DHCPv6报文中不含有Second VLAN,则Option 18中也不包含Second VLAN ID内容。
¡ DUID:缺省为设备本身的DUID信息,可通过命令行配置为其它DUID信息。
Option 37称为远程ID选项(Remote ID),设备接收到DHCPv6客户端发送的DHCPv6请求报文后,在该报文中添加Option 37选项(DHCPv6中继会在Relay-forwad报文中添加Option 37选项),并转发给DHCPv6服务器。服务器可根据Option 37选项中的信息对DHCPv6客户端定位,为分配IPv6地址提供帮助。图10为Option 37选项格式。
图10 Option 37选项格式
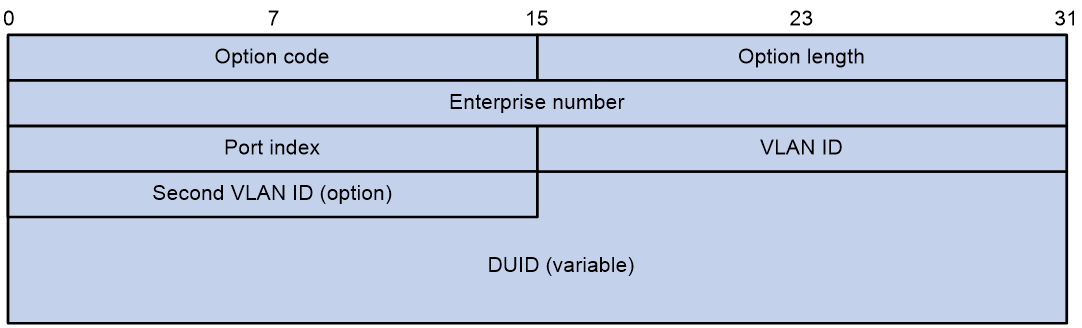
各字段的解释如下:
¡ Option code:Option编号,取值为37。
¡ Option length:Option字段长度。
¡ Enterprise number:企业编号。
¡ Port index:DHCPv6设备收到客户端请求报文的端口索引。
¡ VLAN ID:第一层VLAN信息。
¡ Second VLAN ID:第二层VLAN信息。选项格式中的Second VLAN ID字段为可选,如果DHCPv6报文中不含有Second VLAN,则Option 37中也不包含Second VLAN ID内容。
¡ DUID:缺省为设备本身的DUID信息,可通过命令行配置为其它DUID信息。
Option 79称为客户端链路地址选项(Client link layer address)。DHCPv6请求报文经过第一个DHCPv6中继时,该DHCPv6中继会学习报文的源MAC地址,即DHCPv6客户端的MAC地址。DHCPv6中继生成和请求报文对应的Relay-Forward报文时,会将学到的MAC地址添加到报文的Option 79选项中,再将该报文转发给DHCPv6服务器。DHCPv6服务器可根据Option 79选项中的信息学习DHCPv6客户端的MAC地址,为IPv6地址/IPv6前缀分配或客户端合法性认证提供帮助。图11为Option 79选项格式。
图11 Option 79选项格式

各字段的解释如下:
¡ Option code:Option编号,取值为79。
¡ Option length:Option字段长度。
¡ Link-layer type:客户端链路层地址类型。
¡ Link-layer address:客户端链路层地址。
DNS(Domain Name System,域名系统)是一种用于TCP/IP应用程序的分布式数据库,提供域名与IP地址之间的转换。通过域名系统,用户进行某些应用时,可以直接使用便于记忆的、有意义的域名,而由网络中的域名解析服务器将域名解析为正确的IP地址。
在IPv6网络中,DNS主要使用AAAA和PTR记录来实现域名与IPv6地址的转换。
· AAAA记录:用来将域名映射为IPv6地址,实现正向地址解析。
· PTR记录:用来将IPv6地址映射为域名,实现反向地址解析。
在IPv4网络向IPv6网络迁移的过程中,IPv4网络和IPv6网络在一段时期内将共存。IPv4和IPv6共存网络中,用户访问IPv6网页时,可能会出现天窗问题。
天窗问题是指用户访问IPv6网页时,如果网页中包含其他网站的链接(简称为外链),且该网站属于未进行IPv6改造升级的IPv4网络,则IPv6网页访问会出现响应缓慢、部分内容无法显示、部分功能无法使用等情况。
如图12所示,天窗问题出现的原因为:双栈终端访问IPv6网页时,对于其中包含的IPv4网站链接,双栈终端将其视为IPv6网址,向DNS服务器请求AAAA记录。由于IPv4网站不存在对应的AAAA记录,导致域名解析失败。
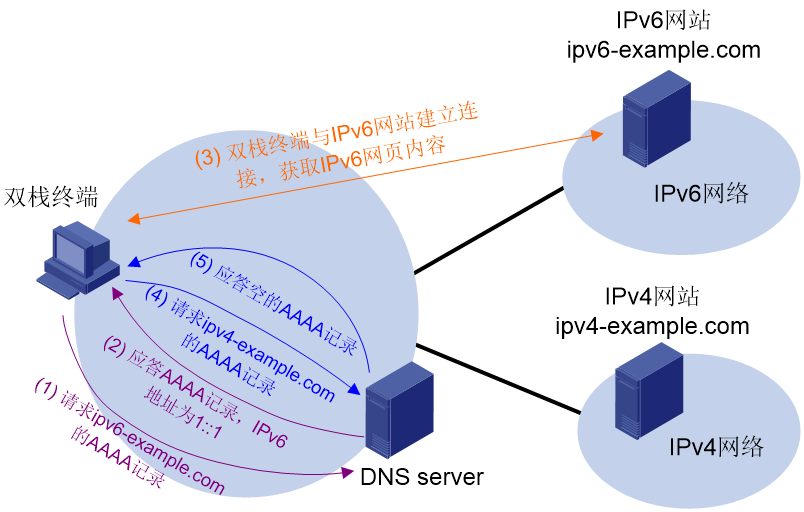
可以通过IPv6域名解析失败、IPv6连接建立失败后,尝试进行IPv4域名解析、建立IPv4连接的方式解决天窗问题。具体工作过程为:
(1) 双栈终端优先发送IPv6 DNS请求,请求IPv6网页内嵌域名的AAAA记录。
(2) 双栈终端随后发送IPv4 DNS请求,请求IPv6网页内嵌域名的A记录。
(3) 如果双栈终端接收到域名服务器回复的AAAA记录,则双栈终端向AAAA记录中的IPv6地址发送连接建立请求,与内嵌网站建立IPv6连接。
(4) 如果双栈终端未收到AAAA记录,或与AAAA记录中的IPv6地址建立连接失败,则双栈终端向A记录中的IPv4地址发送连接建立请求,与内嵌网站建立IPv4连接。
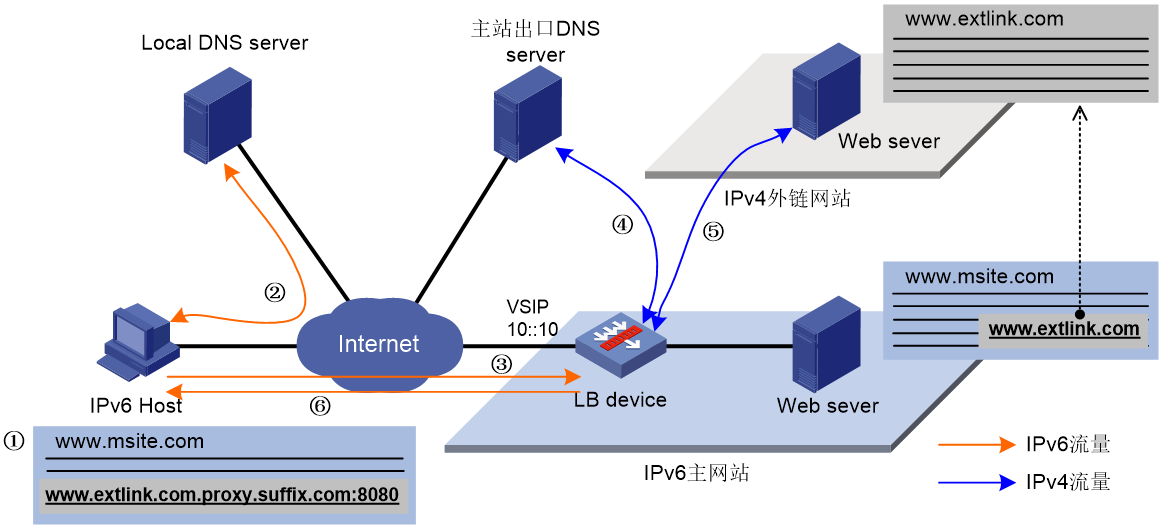
IPv6单栈终端访问IPv6网页时,对于其中包含的IPv4网站链接,客户端浏览器会向本地DNS服务器发送请求外链域名的IPv6 DNS请求报文。由于DNS服务器不存在IPv4网站链接的AAAA记录,域名解析失败,进而出现天窗问题。为了解决上述场景中的天窗问题,需要部署LB设备并在LB设备上配置外链代理功能。
如图13所示,在LB设备上配置外链代理功能后,LB设备在响应IPv6客户端访问主站页面的请求时,会同时向客户端返回外链改写的脚本文件。客户端浏览器执行该脚本文件,对IPv4外链域名进行改写。然后,客户端向本地DNS服务器查询改写后的外链域名。本地DNS服务器根据查询的域名将DNS请求重定向至LB设备,由LB设备代替IPv6客户端请求外链资源,并将外链资源返回给客户端。具体工作过程为:
(1) IPv6 Host浏览器执行脚本文件,将外链域名改写为http://www.extlink.com.proxy.suffix.com。
(2) IPv6 Host向Local DNS server发送查询域名http://www.extlink.com.proxy.suffix.com的DNS请求报文。Local DNS server根据查询结果通知IPv6 Host解析该域名的权威DNS服务器为LB device。
(3) IPv6 Host向LB device发送查询域名http://www.extlink.com.proxy.suffix.com的DNS请求报文。
(4) LB device收到包含改写后域名的DNS请求报文后,代替IPv6 Host向DNS sever发送查询原始外链域名http://www.extlink.com的DNS请求报文,获取外链资源的IPv4地址。
(5) LB device根据外链资源的IPv4地址获取外链资源。
(6) LB device将收到的外链资源发送给IPv6 Host。
浏览器解析获取到的外链资源即可将正常的网页展示给用户。
IPv4网络中常见的路由协议包括RIP、OSPF、IS-IS和BGP。这些路由协议需要进行一定的演变和扩展才能应用于IPv6网络。扩展后的路由协议称为RIPng、OSPFv3、IPv6 IS-IS和IPv6 BGP。IPv4网络和IPv6网络的路由协议在应用场景、路由思路、优劣势等方面并无本质区别,只是为了适应IPv6地址及IPv6网络特点,调整了部分路由工作机制。
RIP有两个版本:RIP-1和RIP-2。
RIP-1是有类别路由协议(Classful Routing Protocol),它只支持以广播方式发布协议报文。RIP-1的协议报文无法携带掩码信息,它只能识别A、B、C类这样的自然网段的路由,因此RIP-1不支持不连续子网。
RIP-2是一种无类别路由协议(Classless Routing Protocol),与RIP-1相比,它有以下优势:
· 支持路由标记,在路由策略中可根据路由标记对路由进行灵活的控制。
· 报文中携带掩码信息,支持路由聚合和CIDR。
· 支持指定下一跳,在广播网上可以选择到最优下一跳地址。
· 支持组播方式发送更新报文,减少资源消耗。
· 在路由更新报文中增加一个认证RTE(Route Entries,路由表项)以支持对协议报文进行验证,并提供明文验证和MD5验证两种方式,增强安全性。
RIPng在工作机制上与RIP-2基本相同,但为了支持IPv6地址格式,RIPng对RIP-2做了一些改动。
· 路由信息中的目的地址和下一跳地址长度不同。
RIP-2报文中路由信息的目的地址和下一跳地址只有32比特,而RIPng均为128比特。
· 报文长度不同。
RIP-2对报文的长度有限制,规定每个报文最多只能携带25个RTE,而RIPng对报文长度、RTE的数目都不作规定,报文的长度与发送接口设置的IPv6 MTU有关。
· 报文格式不同。
RIP-2报文结构如图14所示,由头部(Header)和多个RTE组成。

RIPng报文结构如图15所示。与RIP-2一样,RIPng报文也是由Header和多个RTE组成。与RIP-2不同的是,在RIPng里有两类RTE,分别是:
¡ 下一跳RTE:位于一组具有相同下一跳的IPv6前缀RTE的前面,它定义了下一跳的IPv6地址。
¡ IPv6前缀RTE:位于某个下一跳RTE的后面。同一个下一跳RTE的后面可以有多个不同的IPv6前缀RTE。它描述了RIPng路由表中的目的IPv6地址、路由标记、前缀长度以及度量值。

下一跳RTE的格式如图16所示,其中,IPv6 next hop address表示下一跳的IPv6地址。

IPv6前缀RTE的格式如图17所示,各字段的解释如下:
¡ IPv6 prefix:目的IPv6地址的前缀。
¡ Route tag:路由标记。
¡ Prefix lenth:IPv6地址的前缀长度。
¡ Metric:路由的度量值。
图17 IPv6前缀RTE格式

· 报文的发送方式不同。
RIP-2可以根据用户配置采用广播或组播方式来周期性地发送路由信息;RIPng使用组播方式周期性地发送路由信息。
RIPng自身不提供认证功能,而是通过使用IPv6提供的安全机制来保证自身报文的合法性。因此,RIP-2报文中的认证RTE在RIPng报文中被取消。
RIP-2不仅能在IP网络中运行,也能在IPX网络中运行;RIPng只能在IPv6网络中运行。
OSPFv3在工作机制上与OSPFv2基本相同,但为了支持IPv6地址格式,OSPFv3对OSPFv2做了一些改动。
OSPFv3在协议设计思路和工作机制与OSPFv2基本一致:
· 报文类型相同:包含Hello、DD、LSR、LSU、LSAck五种类型的报文。
· 区域划分相同。
· LSA泛洪和同步机制相同:为了保证LSDB内容的正确性,需要保证LSA的可靠泛洪和同步。
· 路由计算方法相同:采用最短路径优先算法计算路由。
· 网络类型相同:支持广播、NBMA、P2MP和P2P四种网络类型。
· 邻居发现和邻接关系形成机制相同:OSPF路由器启动后,便会通过OSPF接口向外发送Hello报文,收到Hello报文的OSPF路由器会检查报文中所定义的参数,如果双方一致就会形成邻居关系。形成邻居关系的双方不一定都能形成邻接关系,这要根据网络类型而定,只有当双方成功交换DD报文,交换LSA并达到LSDB的同步之后,才形成真正意义上的邻接关系。
· DR选举机制相同:在NBMA和广播网络中需要选举DR和BDR。
为了支持在IPv6环境中运行,指导IPv6报文的转发,OSPFv3对OSPFv2做出了一些必要的改进,使得OSPFv3可以独立于网络层协议,而且只要稍加扩展,就可以适应各种协议,为未来可能的扩展预留了充分的可能。
OSPFv3与OSPFv2不同主要表现在:
· 基于链路的运行。
OSPFv2是基于网络运行的,两个路由器要形成邻居关系必须在同一个网段。
OSPFv3的实现是基于链路,一条链路可以包含多个子网,节点即使不在同一个子网内,只要在同一链路上就可以直接通信。
· 使用链路本地地址。
OSPFv3的路由器使用链路本地地址作为发送报文的源地址。一台路由器可以学习到这条链路上相连的所有其它路由器的链路本地地址,并使用这些链路本地地址作为下一跳来转发报文。但是在虚连接上,必须使用全球范围地址作为OSPFv3协议报文的源地址。
由于链路本地地址只在本链路上有意义且只能在本链路上泛洪,因此链路本地地址只能出现在Link LSA中。
· 链路支持多实例复用。
如图18所示,OSPFv3支持在同一链路上运行多个实例,实现链路复用并节约成本。
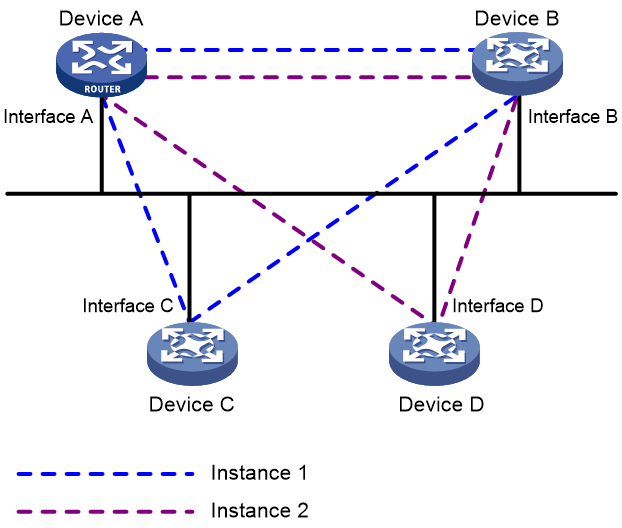
Device A、Device B、Device C和Device D连接到同一个广播网上,它们共享同一条链路。在Device A的Interface A、Device B的Interface B、Device C的Interface C上指定实例1;在Device A的Interface A、Device B的Interface B、Device D的Interface D上指定实例2,实现了Device A、Device B和Device C可以建立邻居关系,Device A、Device B和Device D可以建立邻居关系。
这是通过在OSPFv3报文头中添加Instance ID字段来实现的。如果接口配置的Instance ID与接收的OSPFv3报文的Instance ID不匹配,则丢弃该报文,从而无法建立邻居关系。
· 通过Router ID唯一标识邻居。
在OSPFv2中,当网络类型为点到点或者通过虚连接与邻居相连时,通过Router ID来标识邻居路由器,当网络类型为广播或NBMA时,通过邻居接口的IP地址来标识邻居路由器。
OSPFv3取消了这种复杂性,无论对于何种网络类型,都是通过Router ID来唯一标识邻居。
· 认证的变化。
OSPFv3协议除了自身可以提供认证功能外,还可以通过使用IPv6提供的安全机制来保证自身报文的合法性。
· Stub区域的支持。
由于OSPFv3支持对未知类型LSA的泛洪,为防止大量未知类型LSA泛洪进入Stub区域,对于向Stub区域泛洪的未知类型LSA进行了明确规定:只有当未知类型LSA的泛洪范围是区域或链路而且U比特没有置位时,未知类型LSA才可以向Stub区域泛洪。
· 报文的不同。
OSPFv3报文封装在IPv6报文中,每一种类型的报文均以一个16字节的报文头部开始。
与OSPFv2一样,OSPFv3的五种报文都有同样的报文头,只是报文中的字段有些不同。
OSPFv3的LSU和LSAck报文与OSPFv2相比没有什么变化,但OSPFv3的报文头、Hello与OSPFv2略有不同,报文的改变包括以下几点:
¡ 版本号从2升级到3。
¡ 报文头的不同:与OSPFv2报文头相比,OSPFv3报文头长度只有16字节,去掉了认证字段,但增加了Instance ID字段。Instance ID字段用来支持在同一条链路上运行多个实例,且只在链路本地范围内有效。
¡ Hello报文的不同:与OSPFv2 Hello报文相比,OSPFv3 Hello报文去掉了网络掩码字段,增加了Interface ID字段,用来标识发送该Hello报文的接口ID。
· Option字段不同。
在OSPFv2中,Option字段出现在每一个Hello报文、DD报文以及每一个LSA中。
在OSPFv3中,Option字段只在Hello报文、DD报文、Router LSA、Network LSA、Inter Area Router LSA以及Link LSA中出现。
OSPFv2的Option字段如图19所示。
![]()
OSPFv3的Option字段如图20所示。
![]()
从上图可以看出,与OSPFv2相比,OSPFv3的Option字段增加了R比特、V比特。其中:
¡ R比特:用来标识设备是否是具备转发能力的路由器。如果R比特置0,则表示该节点的路由信息将不会参加路由计算。如果当前设备不想转发目的地址不是本地地址的报文,可以将R比特置0。
¡ V比特:如果V比特置0,该路由器或链路不会参加路由计算。
· LSA类型格式不同。
OSPFv3支持七种类型的LSA。OSPFv3 LSA与OSPFv2 LSA的异同如表4所示。
表4 OSPFv3与OSPFv2 LSA的异同点
|
OSPFv2 LSA |
OSPFv3 LSA |
与OSPFv2 LSA异同点说明 |
|
Router LSA |
Router LSA |
名称相同,作用也类似,但是不再描述地址信息,仅仅用来描述路由域的拓扑结构 |
|
Network LSA |
Network LSA |
|
|
Network Summary LSA |
Inter Area Prefix LSA |
作用类似,名称不同 |
|
ASBR Summary LSA |
Inter Area Router LSA |
|
|
AS External LSA |
AS External LSA |
作用与名称完全相同 |
|
无 |
Link LSA |
新增LSA |
|
Intra Area Prefix LSA |
新增LSA |
OSPFv3新增了Link LSA和Intra Area Prefix LSA。
¡ Router LSA不再包含地址信息,使能OSPFv3的路由器为它所连接的每条链路产生单独的Link LSA,将当前接口的链路本地地址以及路由器在这条链路上的一系列IPv6地址信息向该链路上的所有其它路由器通告。
¡ Router LSA和Network LSA中不再包含路由信息,这两类LSA中所携带的路由信息由Intra Area Prefix LSA来描述,该类LSA用来公告一个或多个IPv6地址前缀。
· LSA处理方式不同。
OSPFv3扩大了LSA的泛洪范围。LSA的泛洪范围已经被明确地定义在LSA的LS Type字段。目前,有三种LSA泛洪范围:
¡ 链路本地范围:LSA只在本地链路上泛洪,不会超出这个范围,该范围适用于新定义的Link LSA。
¡ 区域范围:LSA的泛洪范围仅仅覆盖一个单独的OSPFv3区域。Router LSA、Network LSA、Inter Area Prefix LSA、Inter Area Router LSA和Intra Area Prefix LSA都是区域范围泛洪的LSA。
¡ 自治系统范围:LSA将被泛洪到整个路由域,AS External LSA就是自治系统范围泛洪的LSA。
支持对未知类型LSA的处理方式不同。在OSPFv2中,收到类型未知的LSA将直接丢弃。OSPFv3在LSA的LS Type字段中增加了一个U比特位来位标识对未知类型LSA的处理方式:
¡ 如果U比特置1,则对于未知类型的LSA按照LSA中的LS Type字段描述的泛洪范围进行泛洪。
¡ 如果U比特置0,对于未知类型的LSA仅在链路范围内泛洪。
· LSA格式不同。
为了适应IPv6地址长度和地址类型等需求,OSPFv3对LSA头及各类LSA的格式进行了调整,详细介绍请参见《OSPFv3技术白皮书》。
为了支持在IPv6环境中运行,指导IPv6报文的转发,IPv6 IS-IS采用NLPID(Network Layer Protocol Identifier,网络层协议标识符)值142(0x8E)来标识IPv6协议,并通过对IS-IS TLV进行简单的扩展,使其能够处理IPv6的路由信息。
TLV(Type-Length-Value)是LSP(Link State PDU,链路状态协议数据单元)中的一个可变长字段值。为了支持IPv6路由的处理和计算,IS-IS新增了两个TLV,分别是:
· IPv6可达性TLV(IPv6 Reachability TLV)
类型值为236(0xEC),通过定义路由信息前缀、度量值等信息来说明网络的可达性。IPv6 IS-IS中的IPv6可达性TLV对应于IS-IS中的普通可达性TLV和扩展可达性TLV,格式如图21所示。
图21 IPv6可达性TLV
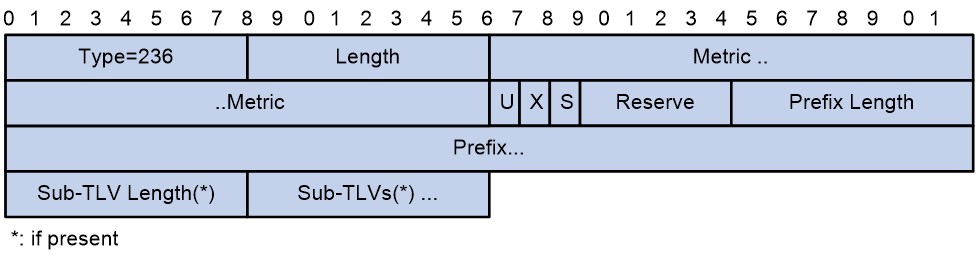
主要字段的解释如下:
¡ Type:取值为236,表示该TLV是IPv6可达性TLV。
¡ Length:TLV长度。
¡ Metric:度量值,使用扩展的Metric值,取值范围为0~4261412864。度量值大于4261412864的IPv6可达性信息都被忽略掉。
¡ U:up/down状态标志位,用来防止路由环路。当某条路由从Level-2路由器传播到Level-1路由器时,这个位被置为1,从而保证了该路由不会被回环。
¡ X:外部路由引入标识,取值1表示该路由是从其它协议引入的。
¡ S:当TLV中不携带Sub-TLV时,S位置“0”;当S位置“1”时,表示IPv6前缀后面跟随Sub-TLV信息。
¡ Reserve:保留位。
¡ Prefix Length:IPv6路由的前缀长度。
¡ Prefix:该路由器可以到达的IPv6路由前缀。
¡ Sub-TLV Length/Sub-TLVs:Sub-TLV字段长度以及Sub-TLVs字段,该选项用于以后扩展用。
· IPv6接口地址TLV
类型值为232(0xE8),它对应于IPv4中的IP Interface Address TLV,只不过把原来的32比特的IPv4地址改为128比特的IPv6地址。IPv6接口地址TLV对应于IS-IS中的IPv4接口地址TLV,格式如图22所示。
图22 IPv6接口地址TLV
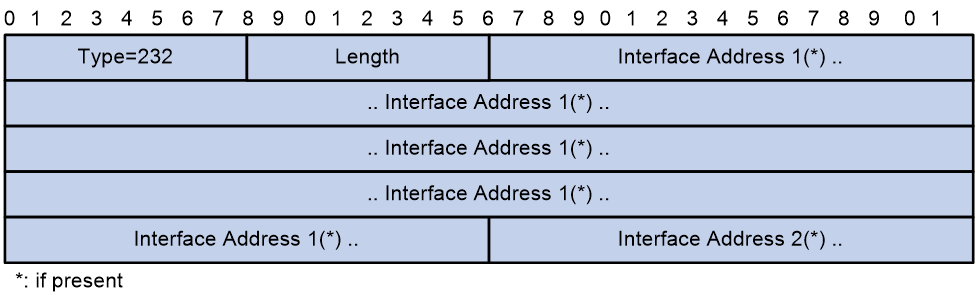
主要字段的解释如下:
¡ Type:取值为232,表示该TLV类型是IPv6接口地址TLV。
¡ Length:TLV长度。
¡ Interface Address:使能IPv6 IS-IS功能接口的IPv6地址,Hello报文中接口IPv6地址TLV填入的是接口的IPv6链路本地地址,LSP报文中填入的是接口的非IPv6链路本地地址,即接口的IPv6全球单播地址。
IS-IS使用Hello报文来发现同一条链路上的邻居路由器并建立邻接关系,当邻接关系建立完毕后,将继续周期性地发送Hello报文来维持邻接关系。为了支持IPv6路由,建立IPv6邻接关系,IPv6 IS-IS对Hello报文进行了扩充:
· NLPID是标识IS-IS支持何种网络层协议的一个8比特字段,IPv6 IS-IS对应的NLPID值为142(0x8E)。如果设备支持IPv6 IS-IS功能,那么它必须在Hello报文中携带该值向邻居通告其支持IPv6。
· 在Hello报文中添加IPv6接口地址TLV,Interface Address字段填入使能了IPv6 IS-IS功能接口的IPv6链路本地地址。
IPv6 BGP利用BGP的多协议扩展属性,来实现在IPv6网络中跨自治系统传播IPv6路由。
BGP-4中与IPv4网络层协议相关的信息由Update消息携带,这些信息是:NLRI和NEXT_HOP属性等路径属性。
为实现对IPv6的支持,IPv6 BGP在NLRI和NEXT_HOP属性基础上进行了扩展:
· 引入两个新的路径属性MP_REACH_NLRI和MP_UNREACH_NLRI,用以代替BGP-4的NLRI字段,以提供对IPv6地址前缀的BGP路由的支持。
· 下一跳信息新增对IPv6地址的支持,下一跳信息中不仅可以携带全球单播IPv6地址,还可以携带链路本地地址。IPv6 BGP的下一跳信息通过MP_REACH_NLRI属性携带,而不是在NEXT_HOP属性中携带。
在尚未完全演进的IPv4/IPv6混合网络中,IPv6 BGP提供了通过BGP IPvX会话承载IPv6的能力,使得设备可以在IPv4会话上交互IPv6 BGP路由,亦可以在IPv6会话上交互IPv4 BGP路由,为IPv4/IPv6网络提供了扩展支持IPv6/IPv4流量转发的能力。
IPv4和IPv6路由协议的主要异同点如所示。
表5 IPv4和IPv6路由协议的主要异同点
|
协议类型 |
相同点 |
主要差异点 |
|
RIP/RIPng |
路由计算思路、基本工作机制相同 |
· 报文格式的差异(组播地址、UDP端口、协议报文格式) · 路由下一跳处理的差异 · RIPng的安全控制由IPv6报头实现 |
|
OSPFv2/OSPFv3 |
路由计算思路、基本工作机制相同 |
· OSPFv3修改了LSA的种类和格式,使其支持发布IPv6路由信息 · OSPFv3修改部分协议流程,使其独立于网络协议,大大提高了可扩展性 · OSPFv3支持处理未知类型LSA,提高了协议对未来扩展的适应性 |
|
IS-IS/IPv6 IS-IS |
协议架构相同 |
· IPv6 IS-IS在Hello报文中新定义了支持IPv6的网络层协议标识符NLPID(类型值为142) · IPv6 IS-IS新增IPv6接口地址TLV和IPv6可达性TLV |
|
BGP-4/IPv6 BGP |
协议架构相同 |
· IPv6 BGP扩展Open消息,使其支持IPv6能力协商 · IPv6 BGP扩展了支持IPv6地址的MP_REACH_NLRI、MP_UNREACH_NLRI和Nexthop属性 |
与按照报文目的地址查找路由表进行转发的路由协议不同,策略路由是一种依据用户制定的策略进行转发的机制。策略路由可以对于满足一定条件(例如ACL规则)的报文,执行指定的操作(设置报文的下一跳、出接口、缺省下一跳和缺省出接口等)。
双栈策略路由与单栈策略路由(包括IPv4策略路由和IPv6策略路由)在报文的转发流程上基本相同,主要区别在于单栈策略路由只能处理IPv4或IPv6一种报文,而双栈策略路由支持同时处理IPv4和IPv6两种报文。
在双协议栈节点使用双栈策略路由可以减少配置的复杂度,同时节省一定的驱动资源。
组播是指在IP网络中将数据包以尽力传送的形式发送到某个确定的节点集合(即组播组),其基本思想是:源主机(即组播源)只发送一份数据,其目的地址为组播组地址;组播组中的所有接收者都可收到同样的数据拷贝,并且只有组播组内的主机可以接收该数据,其它主机无法接收。
组播技术有效地解决了单点发送、多点接收的问题,实现了IP网络中点到多点的高效数据传送,能够大量节约网络带宽、降低网络负载。作为一种与单播和广播并列的通信方式,组播的意义不仅在于此。更重要的是,可以利用网络的组播特性方便地提供一些新的增值业务,如在线直播、网络电视、远程教育、远程医疗、网络电台、实时视频会议等互联网的信息服务领域。
IPv6组播与IPv4组播的最大不同在于IPv6组播地址机制的极大丰富,而其它诸如组成员管理、组播报文转发以及组播路由建立等与IPv4组播基本相同。因此,本文将重点介绍组播地址对IPv6的支持情况;对于IPv6组播协议,只对其与IPv4组播协议的异同进行大致的介绍。
在介绍IPv6组播地址之前,先简单回顾一下IPv6的地址结构:IPv6地址的长度为128比特,每个IPv6地址被分为8组,每组的16比特用4个十六进制数来表示,组和组之间用冒号隔开,例如:FEDC:BA98:7654:3210:FEDC:BA98:7654:3210。
IPv6组播地址用来标识一组接口,通常这些接口属于不同的节点。一个节点可能属于0到多个组播组。发往组播地址的报文被组播地址标识的所有接口接收。
图23 IPv6组播地址格式
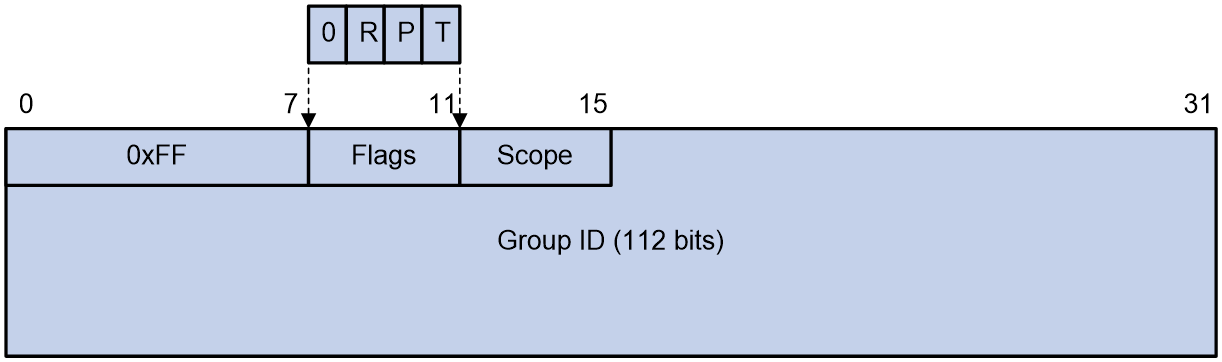
如图23所示,IPv6组播地址中各字段的含义如下:
· 0xFF:最高8比特为11111111,标识此地址为IPv6组播地址。
· Flags:4比特,该字段中各位的取值及含义如表6所示。
表6 Flags字段各位的取值及含义
|
位 |
取值及含义 |
|
0位 |
保留位,必须取0 |
|
R位 |
· 取0表示非内嵌RP的IPv6组播地址 · 取1表示内嵌RP的IPv6组播地址(此时P、T位也必须置1) |
|
P位 |
· 取0表示非基于单播前缀的IPv6组播地址 · 取1表示基于单播前缀的IPv6组播地址(此时T位也必须置1) |
|
T位 |
· 取0表示由IANA永久分配的IPv6组播地址 · 取1表示非永久分配的IPv6组播地址 |
· Scope:4比特。用来标识该IPv6组播组的应用范围,其取值及含义如表7所示。
表7 Scope字段的取值及其含义
|
取值 |
含义 |
|
0、F |
保留(Reserved) |
|
1 |
接口本地范围(Interface-Local Scope) |
|
2 |
链路本地范围(Link-Local Scope) |
|
3 |
子网本地范围(Subnet-Local Scope) |
|
4 |
管理本地范围(Admin-Local Scope) |
|
5 |
站点本地范围(Site-Local Scope) |
|
6、7、9~D |
未分配(Unassigned) |
|
8 |
机构本地范围(Organization-Local Scope) |
|
E |
全球范围(Global Scope) |
· Group ID:112比特,IPv6组播组标识号。用来在由Scope字段所指定的范围内唯一标识IPv6组播组,该标识可能是永久分配的或临时的,这由Flags字段的T位决定。
根据RFC 4291,目前已被预留的IPv6组播地址如表8所示。
表8 预留的IPv6组播地址列表
|
名称 |
地址 |
说明 |
|
保留组播地址 |
FF0X:: |
不能分配给任何组播组 |
|
所有节点组播地址 |
· FF01::1(节点本地) · FF02::1(链路本地) |
- |
|
所有路由器组播地址 |
· FF01::2(节点本地) · FF02::2(链路本地) · FF05::2(站点本地) |
- |
|
被请求节点组播地址 |
FF02::1:FFXX:XXXX |
在被请求节点单播或任播IPv6地址的低24位前增加地址前缀FF02::1:FF00::/104而得,如4037::01:800:200E:8C6C对应于FF02::1:FF0E:8C6C |
![]()
表8中的X代表0~F的任意一个十六进制数。
RFC 3306中规定了一种动态分配IPv6组播地址的方式——基于单播前缀的IPv6组播地址。这种IPv6组播地址中包含了其组播源网络的单播地址前缀,通过这种方式分配全局唯一的组播地址。
图24 基于单播前缀的IPv6组播地址格式
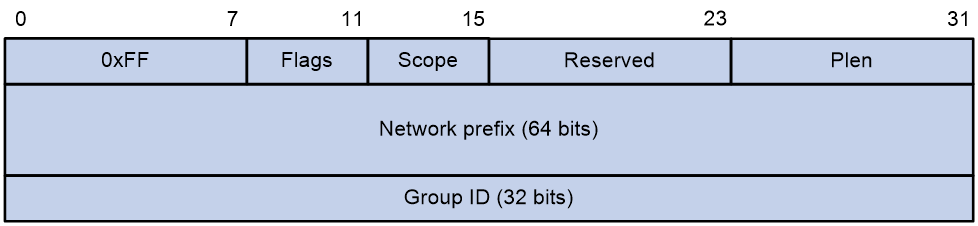
基于单播前缀的IPv6组播地址的格式如图24所示,其中各字段的含义如下:
· Flags:R位置0,P、T位则分别置1,表示基于单播前缀的组播地址。
· Scope:如1. 图23表7所示。
· Reserved:8比特。保留字段,必须为0。
· Plen:8比特。表示网络前缀的有效长度(单位为比特)。
· Network prefix:64比特。表示该组播地址所属子网的单播前缀,有效长度由Plen字段指定。
· Group ID:32比特。表示IPv6组播组标识号。
例如:单播前缀为3FFE:FFFF:1::/48的网络分配基于单播前缀的组播地址为FF3X:30:3FFE:FFFF:1::/96(X表示任意合法的Scope)。
· 地址格式
嵌入式RP(Rendezvous Point,汇集点)是IPv6 PIM中特有的RP发现机制,该机制使用内嵌RP地址的IPv6组播地址,使得组播路由器可以直接从该地址中解析出RP的地址。
图25 内嵌RP地址的IPv6组播地址格式
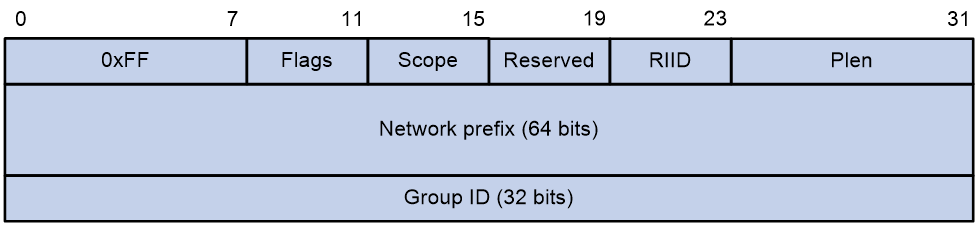
如图25所示,内嵌RP地址的IPv6组播地址使用基于单播前缀的IPv6组播地址格式,其中各字段的含义如下:
¡ Flags:R、P和T位均置1,表示内嵌RP地址的组播地址。
¡ Scope:如1. 图23表7所示。
¡ Reserved:4比特。保留字段,必须为0。
¡ RIID:4比特。表示RP地址的接口ID。
¡ Plen:8比特。表示RP地址前缀的有效长度(单位为比特)。
¡ Network prefix:64比特。表示RP地址前缀,有效长度由Plen字段指定。
¡ Group ID:32比特。表示IPv6组播组标识号。
· 计算规则
内嵌于IPv6组播地址中的RP地址的计算规则如下:
a. 先将IPv6组播地址Network prefix字段的前Plen位作为RP地址的网络前缀。
b. 再将IPv6组播地址RIID字段填充到RP地址的最低4位。
c. 最后,将RP地址的所有剩余位补0。
例如:对于IPv6组播地址FF7E:F40:2001:DB8:BEEF:FEED::1234,内嵌于其中的RP地址的前缀为Network prefix字段的前Plen(这里为0x40 = 64 bits)位,最低4位为RIID(0xF),其余位均为0,如图26所示。
图26 嵌入式RP计算举例

· 应用举例
假设网络管理员想在2001:DB8:BEEF:FEED::/64网段中设置RP,则内嵌RP地址的IPv6组播地址为FF7X:Y40:2001:DB8:BEEF:FEED::/96,可分配32比特的Group ID,内嵌于其中的RP地址为2001:DB8:BEEF:FEED::Y/64。
如果网络管理员想在IPv6组播地址中保留更多可分配的Group ID,可以选择更短的RP地址前缀:譬如取Plen = 0x20 = 32 bits,则此时内嵌RP地址的IPv6组播地址为FF7X:Y20:2001:DB8::/64,可分配64比特的Group ID,内嵌于其中的RP地址为2001:DB8::Y/32。
![]()
X表示任意合法的Scope,Y代表1~F的任意一个十六进制数。
IPv6 SSM(Source-Specific Multicast,指定信源组播)组播地址也使用基于单播前缀的IPv6组播地址格式,其中的Plen字段和Network prefix字段均取0。IPv6 SSM组播地址范围为FF3X::/32(X表示任意合法的Scope)。
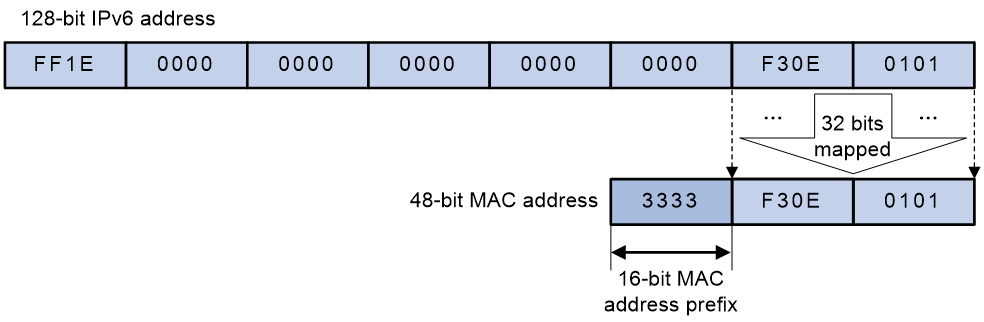
IPv6组播MAC地址以0x3333开头,低32位为IPv6组播地址的低32位,最终形成48比特的组播MAC地址。如图27所示,IPv6组播地址FF1E::F30E:101所对应的组播MAC地址为33-33-F3-0E-01-01。
图27 IPv6组播地址的MAC地址映射举例
IPv6支持的组播协议包括MLD(Multicast Listener Discovery Protocol,组播侦听者发现协议)、MLD Snooping(Multicast Listener Discovery Snooping,组播侦听者发现协议窥探)、IPv6 PIM(IPv6 Protocol Independent Multicast,IPv6协议无关组播)和IPv6 MBGP(IPv6 Multicast BGP,IPv6组播BGP)等。
MLD源自IGMP(Internet Group Management Protocol,互联网组管理协议),MLD有两个版本:MLDv1源自IGMPv2,MLDv2源自IGMPv3。
与IGMP采用IP协议号为2的报文类型不同,MLD采用ICMPv6(IP协议号为58)的报文类型,包括MLD查询报文(类型值130)、MLDv1报告报文(类型值131)、MLDv1离开报文(类型值132)和MLDv2报告报文(类型值143)。MLD协议与IGMP协议除报文格式不同外,协议行为完全相同。
IPv6 PIM与PIM除报文中IP地址结构不同外,其它协议行为基本相同,IPv6 PIM也支持如下四种模式:
· IPv6 PIM-DM(IPv6 Protocol Independent Multicast-Dense Mode,IPv6协议无关组播—密集模式)
· IPv6 PIM-SM(IPv6 Protocol Independent Multicast-Sparse Mode,IPv6协议无关组播—稀疏模式)
· IPv6 PIM-SSM(IPv6 Protocol Independent Multicast Source-Specific Multicast,IPv6协议无关组播-指定源组播)
· IPv6 BIDIR-PIM(IPv6 Bidirectional Protocol Independent Multicast,IPv6双向协议无关组播,简称IPv6双向PIM)
IPv6 PIM发送链路本地范围的协议报文(包括PIM Hello、Join-Prune、Assert、Bootstrap、Graft、Graft-Ack和State-refresh报文)时,报文的源IPv6地址使用发送接口的链路本地地址;IPv6 PIM发送全球范围的协议报文(包括Register、Register-Stop和C-RP Advertisement报文)时,报文的源IPv6地址使用发送接口的全球单播地址。
IPv6组播并不支持MSDP协议,如果需要接收来自其它IPv6 PIM域的组播数据,有以下两种实现方式:
· 通过其它方式(譬如广告等)直接获取其它IPv6 PIM域内的组播源地址,使用IPv6 PIM-SSM发起指定源组的加入。
· 使用嵌入式RP机制,通过嵌入RP地址的IPv6组播地址来获取其它IPv6 PIM域内的RP地址,向其它域内的RP发起组加入。
对于域间IPv6组播路由信息的传递,则可以使用IPv6的MBGP协议,其与IPv4的MBGP协议也基本相同。
· MLD Snooping
MLD Snooping与IGMP Snooping协议基本相同。
· IPv6 PIM Snooping
IPv6 PIM Snooping与PIM Snooping协议基本相同。
· 组播VLAN
组播VLAN,对于IPv4组播和IPv6组播,处理原理相同。
在IPv4网络完全过渡到IPv6网络之前,若用户主机同时支持IPv4和IPv6两种协议,可能会产生两种地址协议类型的流量分别触发对应协议栈的IPoE Web认证或Portal认证。如果用户只通过IPv4或IPv6其中一种认证,就只能访问对应协议栈的网络资源。如果用户需要进行两次不同协议类型的认证,又会增加用户上网操作的复杂度。
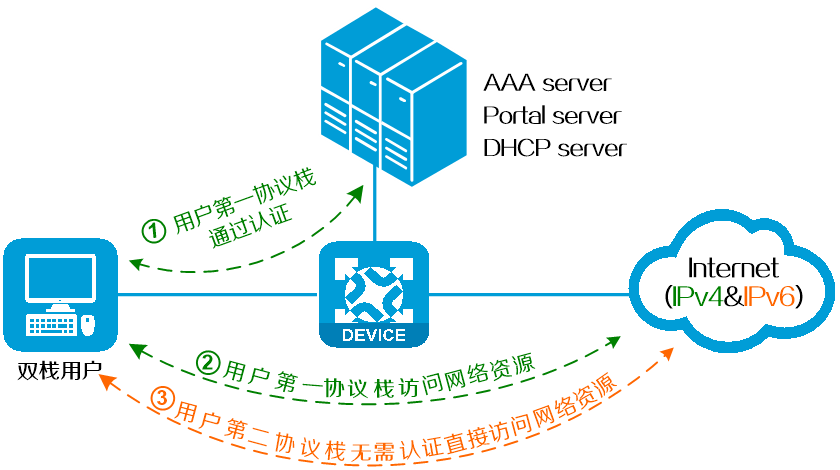
IPoE Web认证或Portal认证支持双栈技术可以很好地解决上述问题,它可以实现一次认证双栈放行,即当双栈用户通过任意一个协议栈(IPv4或IPv6)流量触发认证并成功上线后,它的另外一个协议栈流量无需认证即被放行。
图28 一次认证双栈放行示意图
该技术为IPv6网络带来如下技术价值:
· 对于用户,两个协议栈上线只需要完成一次认证过程,提升使用体验。
· 对于服务器,用户双栈上线只需要进行一次认证,减轻了AAA服务器和Portal服务器的认证压力。
· 对于管理员,同一用户的IPv4和IPv6协议栈作为一个双栈用户进行处理,降低了网络管理和维护的复杂度。
在IPoE Web双栈认证组网中,双栈用户上线的基本过程如下:
(1) 用户通过第一协议栈(如IPv4)上线时,在认证页面中输入用户名和密码,认证通过后可访问相应协议栈的网络资源。设备上记录该用户的MAC地址、用户名和认证状态等信息。
(2) 用户通过第二协议栈(如IPv6)上线时,设备根据用户的MAC地址判断该用户的另一协议栈是否已上线。如上线,则视为同一用户,第二协议栈无需再次认证,直接放行。
根据用户两个协议栈上线方式的不同,IPoE Web双栈认证支持如下三种典型应用场景:
· 动态双栈用户上线:双栈用户可以通过未知源IPv4报文、未知源IPv6报文、DHCPv4报文、DHCPv6报文或ND RS报文触发动态上线。该方式多用于移动终端非固定IP的场景。例如,学生通过移动智能终端接入校园网。
· 静态双栈用户上线:双栈用户可以通过IPv4报文、IPv6报文、ARP报文NS报文或NA报文触发静态上线。该方式多用于终端IP地址固定的场景。例如,学生在宿舍通过固定网口接入校园网。
· 混合双栈用户上线:双栈用户的一个协议栈采用静态方式上线,另一个协议栈采用动态方式上线。该方式多用于网络中同时存在固定IP和非固定IP终端的场景。例如,某高校的原有的IPv4网络用户采用静态IPv4地址方式,学校对现网进行IPv6改造升级后,使得原有IPv4用户可以接入IPv6网络,同时希望用户的IPv6地址通过DHCPv6动态分配,即采用静态IPv4+动态IPv6的混合地址分配方式。
在Portal双栈认证组网中,管理员根据现网的实际需求,在使能了Portal认证的接口上开启Portal支持双栈认证功能后,该接口上的用户只需要通过IPv4 Portal或IPv6 Portal认证中的任何一种,就可以访问IPv4和IPv6两种协议栈对应的网络资源。
Portal双栈用户上线的基本过程如下:
(1) 双栈用户的第一协议栈(IPv4或IPv6)报文触发Portal认证后,用户在Portal Web认证页面中输入用户名和密码,之后若通过IPv4或IPv6 Portal认证,则可访问对应协议栈的网络资源。
(2) 设备将通过IPv4 Portal认证或IPv6 Portal认证的用户MAC地址和IP地址记录在Portal用户表项中。
(3) 设备收到该用户的第二协议栈(IPv6或IPv4)任意报文时,如果报文中的源MAC地址与记录在Portal用户表项中的MAC地址相同,则允许其访问对应协议栈的网络资源,不需要再次进行认证。
![]()
仅当接口上同时开启了直接认证方式的IPv4 和IPv6 Portal认证功能,Portal支持双栈认证功能才会生效。
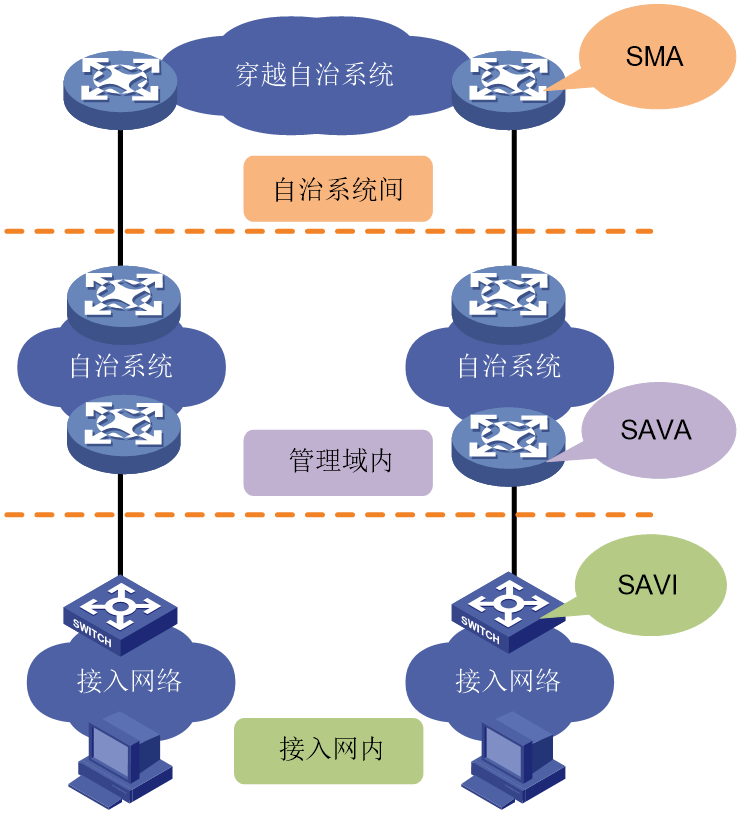
真实IPv6源地址验证是指,通过对报文的IPv6源地址进行验证,丢弃伪造IPv6源地址的报文,提升IPv6网络的安全性。SAVI&SAVA均属于真实IPv6源地址验证技术,分别部署在不同的网络位置,能够满足不同粒度的安全需求。
根据在网络中部署位置的不同,真实IPv6源地址验证功能分为如下三种类型:
· SAVI(Source Address Validation Improvement,源地址有效性验证):部署在接入网,在接入层面提供主机粒度的源地址验证,保证主机只使用合法分配的IPv6地址。
· SAVA(Source Address Validation Architecture,源地址验证架构):部署在骨干网连接接入网的边界设备上,在管理域内提供IPv6前缀粒度的保护能力,以保护核心设备不被仿冒源地址的非法主机攻击。
· SMA(State Machine based Anti-spoofing,基于状态机的伪造源地址检查) :部署在AS间,在AS域间提供AS粒度的源地址验证能力,以保护本AS内的主机和服务器不被仿冒源地址的非法主机攻击。
图29 SAVI&SAVA&SMA在网络中部署位置示意图
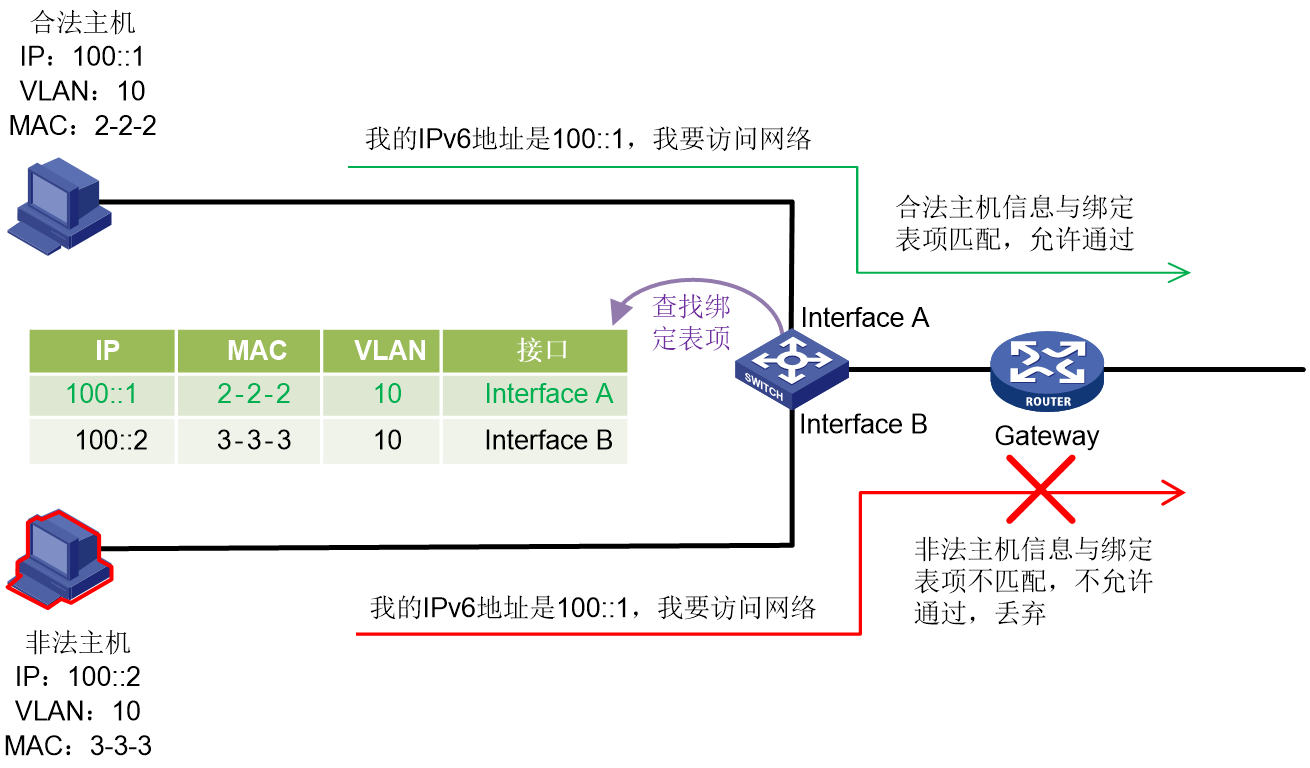
为了防止IPv6源地址非法的DHCPv6协议报文、ND协议报文和IPv6数据报文形成攻击,可以在设备上开启SAVI功能。设备在其它安全功能的配合下,生成绑定表项,并根据该绑定表项对报文IPv6源地址进行检查。如果报文信息与某绑定表项匹配,则认为该报文为合法报文,正常转发;否则将该报文丢弃。
与SAVI配合使用的安全功能包括DHCPv6 Snooping、ND Snooping和IP Source Guard中IPv6静态绑定表项功能。
图30 SAVI原理图
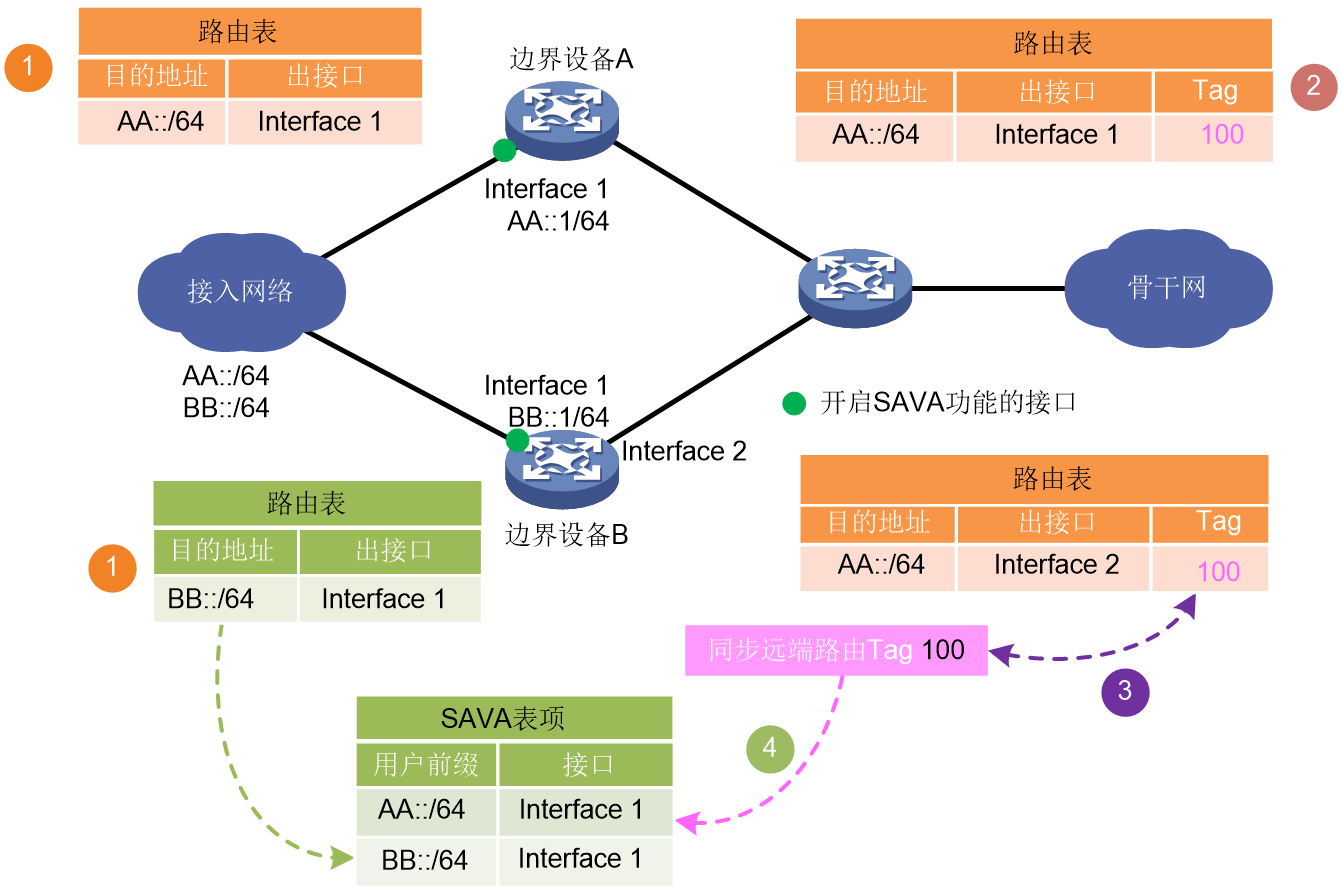
SAVA是一种根据设备的路由信息检查攻击报文的技术,用来防范基于IPv6源地址欺骗的攻击,主要部署在与接入网相连的骨干网内边界设备上。在设备的接入网侧接口上开启SAVA功能后,设备会为该接入网络中的所有的网络前缀生成SAVA表项。该接口收到IPv6报文后,如果存在报文IPv6源地址对应的SAVA表项,则认为该IPv6源地址合法,转发该报文;否则,表示报文IPv6源地址不应该存在于接入网络中,报文非法,被丢弃。
以边界设备B为例,SAVA表项生成过程如图31所示,分为如下几个步骤:
(1) 边界设备A和B分别从本地学习的、到达接入网络的路由信息中获取用户前缀,这些路由信息包括与接入网络相连的直连路由、静态路由和动态路由。本例中以静态路由为例来说明。
(2) 边界设备A为本地学习的、到达接入网络的路由信息打上特定的Tag,并将此路由信息引入骨干网的动态路由协议中。
(3) 边界设备B通过动态路由协议学习到设备A发布的带有Tag的路由信息。如果路由信息中的Tag值与边界设备B上配置的同步远端路由条目的Tag值相同,则边界设备B从该路由信息中获取边界设备A学习到的合法用户前缀信息,用于生成SAVA表项。
(4) 边界设备B将根据本地路由和远端同步路由获取到的所有的合法用户前缀信息来生成与该接口绑定的SAVA表项。SAVA表项信息包含合法用户前缀、前缀长度和绑定的接口。
图31 SAVA表项生成过程
SMA(State Machine based Anti-spoofing,基于状态机的伪造源地址检查)是一种IPv6自治系统间端到端的源地址验证方案,用来防止伪造源IPv6地址的攻击。
(1) 体系结构
SMA体系结构主要由ACS(AS Control Server,AS控制服务器)和AER(AS Edge Router,AS边界路由器)构成,如图32所示。
图32 SMA体系结构
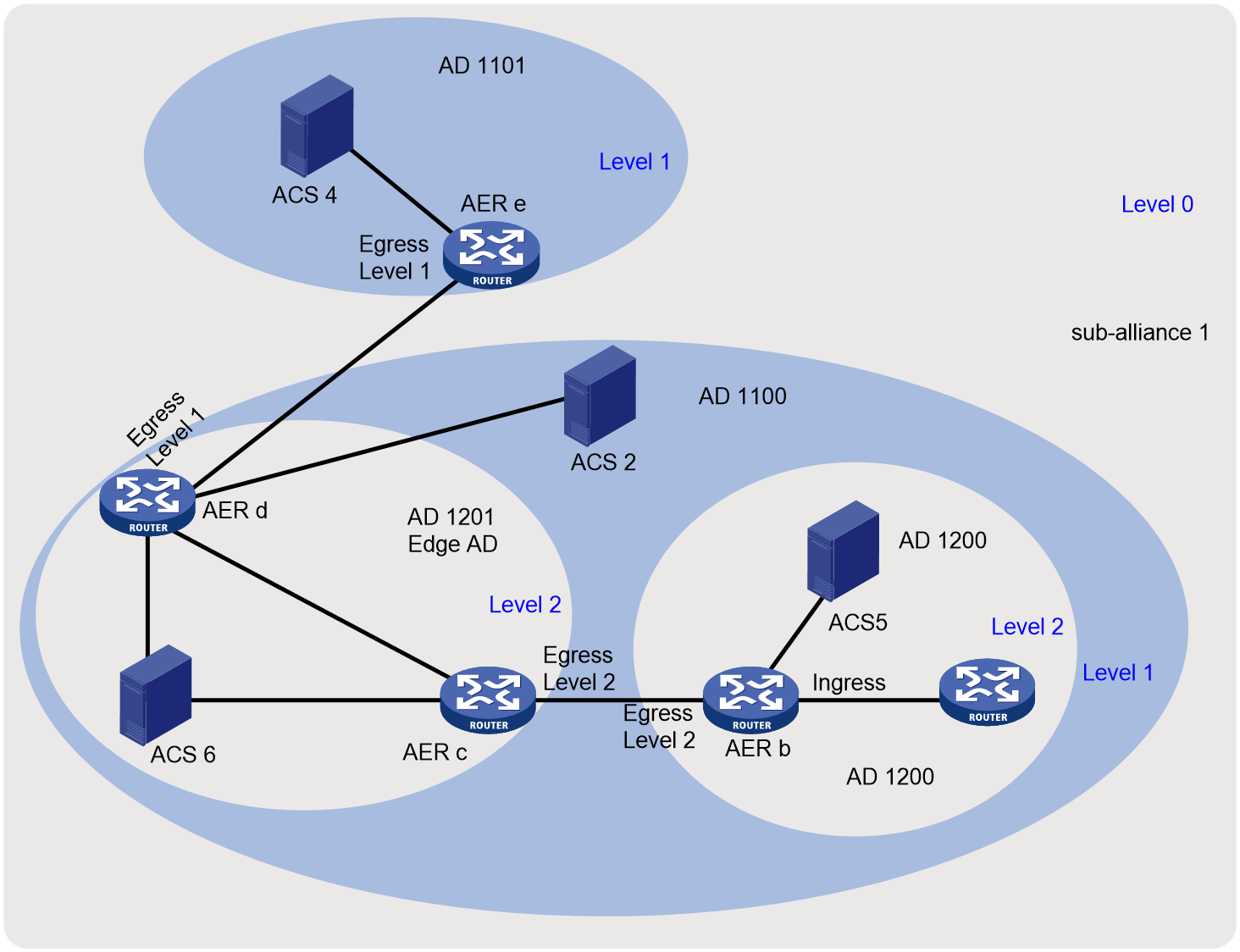
¡ 子信任联盟:彼此信任的一组AD(Addrees Domain,地址域)组成的集合,通过子信任联盟号来标识,比如上图中的sub-alliance 1。
¡ 信任联盟:SMA体系中所有AD的集合。
¡ AD(Addrees Domain,地址域):同一个机构下所管理的所有IP地址部署的范围,是子信任联盟管理的对象,通过地址域编号来标识,比如,上图中的AD 1101、AD 1200和AD 1201。同一个子联盟内的不同的地址域可以分成不同的地址域层级,最多可以划分为4层。比如,上图中的Level 0、Level 1和Level 2。其中,Level 0为最高地址级别,Level 2为最低地址级别。例如,首先以县市为单位划分多个一级地址域,再以机构为单位划分多个二级地址域(比如学校、企事业单位),以楼宇或部门为单位划分三级地址域。
- 边界地址域:当前层级的地址域中与其他层级相连的地址域。比如,上图中的AD 1201。
- 非边界地址域:除了边界地址域的其他地址域。
当一个地址域划分了更低级别的地址域后,原地址域中所有的设备都必须从属于更低级别的地址域中。如上图所示,Level 0的地址域中划分了低一级别的地址域Level 1,那么属于Level 0的所有设备都必须从属于划分后的Level 2地址域。
¡ ACS(AS Control Server,AS控制服务器):每个层级的地址域都需要有相应的ACS,用于和其它地址域内的ACS交互信息,并向本地址域内的AER宣告与更新注册信息、前缀信息以及状态机信息。具体来讲,ACS具有如下功能:
- 与属于相同信任联盟中各子信任联盟的其他ACS建立连接,交互各地址域内的IPv6地址前缀、状态机等信息。
- 向本地址域AER宣告和更新联盟映射关系、地址前缀信息以及标签信息。
¡ AER(AS Edge Router,AS边界路由器):负责接收ACS通告的IPv6地址前缀、标签等信息,并在地址域之间转发报文。一个AER可以是多个不同层级ACS的边界路由器。AER上的接口分为两类:
- Ingress接口:连接到本地址域内部未使能SMA特性的路由器的接口。
- Egress接口:连接其他地址域的AER的Egress接口。
![]()
· 目前,设备只能作为AER。
· 为了提高安全性,ACS与ACS之间、ACS与AER之间的通信均可配置为基于SSL(Secure Sockets Layer,安全套接字层)的连接。
(2) 工作原理
SMA通过在AER上检查报文的源IPv6地址和报文标签实现对伪造源IPv6地址攻击的防御。
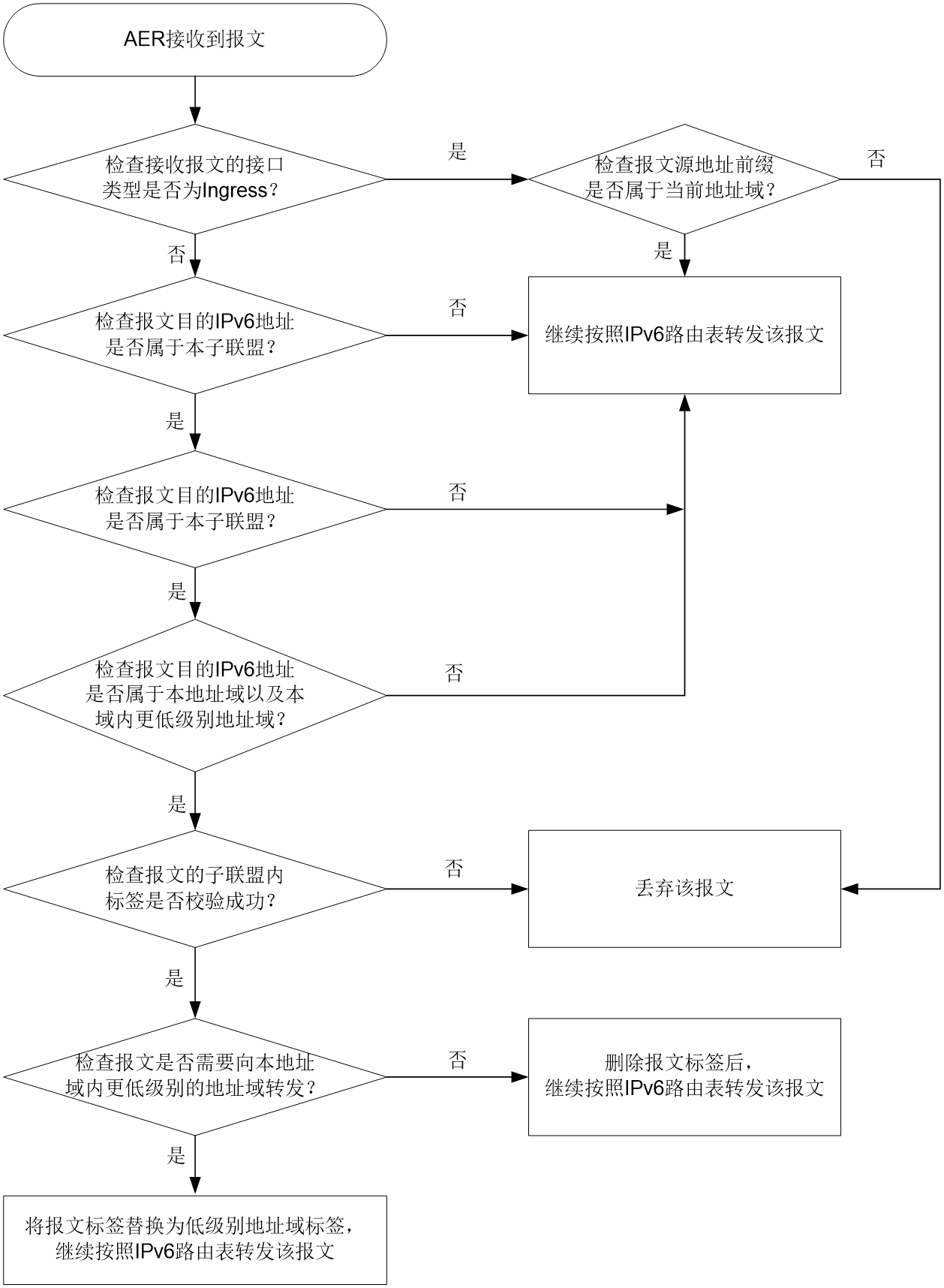
AER接收到报文后,处理过程如图33所示。
a. 检查接收报文的接口类型是否为Ingress。
- 若接口类型是Ingress,则进入步骤b。
- 若接口类型是Egress,则进入步骤c。
- 若属于当前地址域,则继续按照IPv6路由表转发该报文。
- 若不属于当前地址域,则丢弃报文。
c. 检查报文目的IPv6地址是否属于本子联盟:
- 若不属于本子联盟,则继续按照IPv6路由表转发该报文。
- 若属于本子联盟,则进入步骤d。
d. 检查报文的目的IPv6地址是否属于本地址域以及本域内更低级别地址域:
- 若不属于,则继续按照IPv6路由表转发该报文。
- 若属于,则进入步骤e。
- 校验成功,进入步骤f。
- 校验失败,丢弃该报文。
- 若不需要,删除报文标签后,继续按照IPv6路由表转发该报文。
- 若需要,则将报文标签替换为低级别地址域标签,继续按照IPv6路由表转发该报文。
低级别地址域内的AER收到报文后,继续按照如上步骤进行处理。
图33 AER接收报文时的处理过程
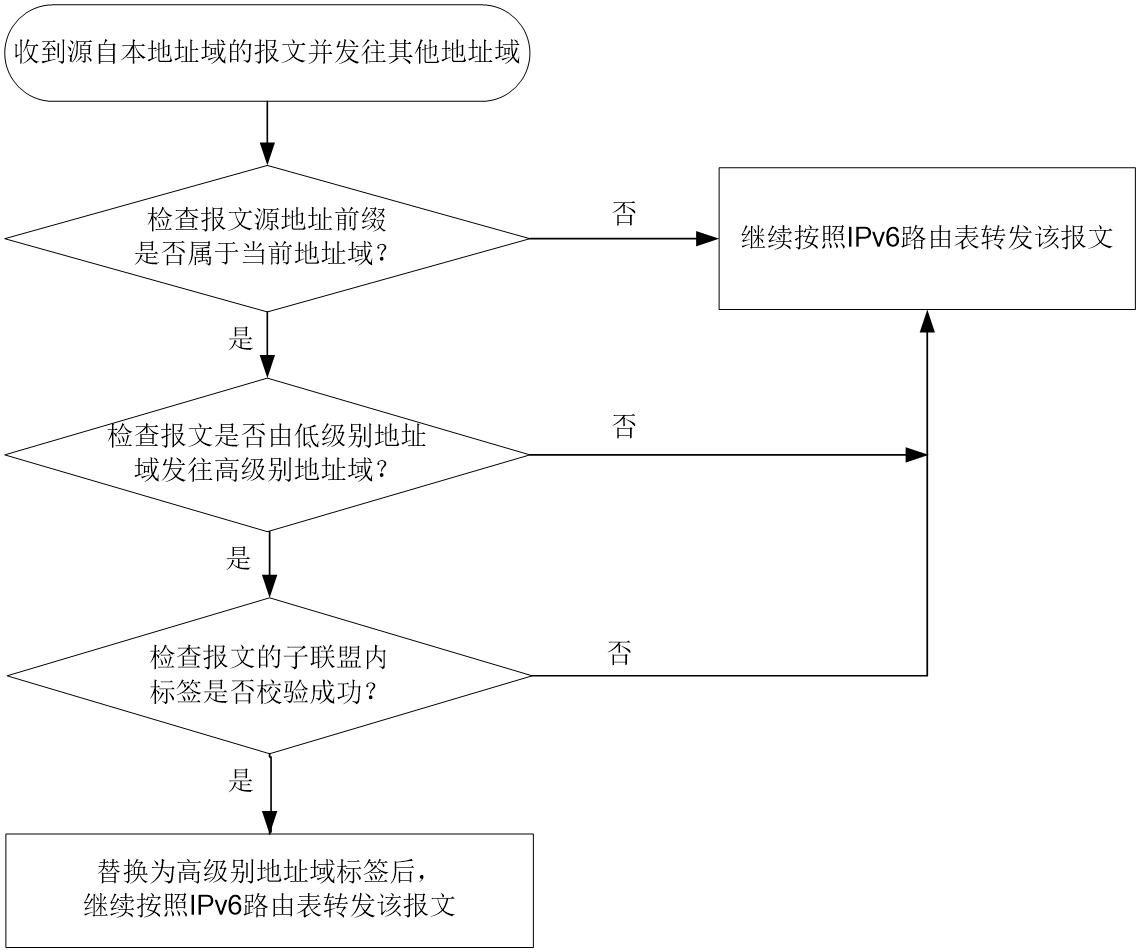
当AER收到源自本地址域的报文并发往其他地址域时,处理过程如图34所示。
a. 判断报文源地址前缀是否属于当前地址域:
- 若属于,对报文添加标签后,继续按照IPv6路由表转发该报文。
- 若不属于,则进入步骤b。
- 若是,则需要校验标签,进入步骤c。
- 若不是,则继续按照IPv6路由表转发该报文。
- 校验成功,替换为高级别地址域标签后,继续按照IPv6路由表转发该报文。
- 校验失败,丢弃该报文。
图34 AER发送报文时的处理过程
随着数据中心的不断发展,数据中心网络内部的流量(即东西向流量)在不断增加, 数据中心网络流量从以前的南北向流量为主转变为东西向流量为主。网络管理员也需要对东西向流量进行安全防控。如果将数据中心内部东西向流量全部绕行传统的集中式防火墙,很难满足数据中心灵活可扩展部署的要求,防火墙容易称为数据中心性能和扩容的瓶颈。
微分段对网络端点(例如数据中心网络中的服务器、虚拟机,或园区网中的各种终端上线用户)进行分组,并部署组间策略,通过组间策略对分属不同组的网络端点之间的通信进行安全管控。这种工作机制决定了它具有管控粒度细和占用ACL资源少的优点。
· 分布式安全:微分段方案实现了分布式的安全控制,东西向流量不需要集中转发到防火墙后再进行安全隔离,减少了网络带宽的消耗,可以防止集中式的防火墙成为流量瓶颈。
· 更精细、灵活的安全隔离:传统的VLAN或IP子网只能实现不同VLAN或子网间的隔离,同一VLAN或子网内的网络端点无法隔离。同时,当不同子网共用同一个网关设备时,网关设备上保存了到各子网的路由信息。在这种情况下,无法完全实现不同子网内不同网络端点之间的隔离。微分段可基于离散IP、IP地址段等进行精细分组,在不同分组之间相应实现更灵活的安全防控。
· 降低ACL资源占用:相较于传统的安全管控技术(主要是利用ACL的安全管控),微分段技术能够显著降低对ACL资源的占用。
图35 ACL资源占用示意图
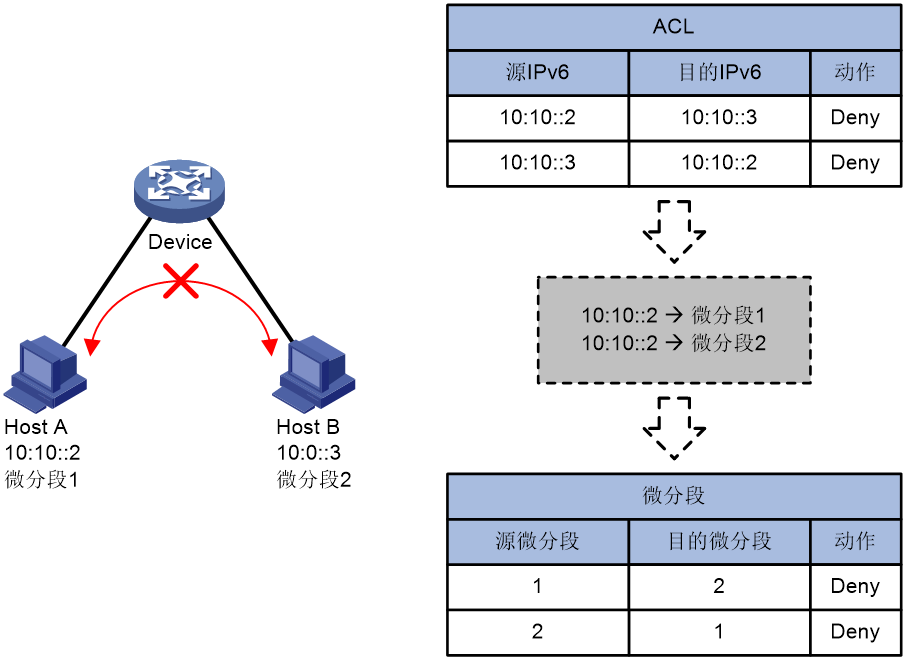
如图35所示,在IPv6网络中,如果期望禁止Host A和Host B互通:
¡ 使用ACL时,需要匹配报文的IP地址。IPv6地址长度为128bits,同时匹配源、目的IP地址时需要占用256bits长度的ACL资源。对双向流量同时进行管控时,则需要占用两条长度为256bits的ACL资源。
¡ 使用微分段时,仅需匹配报文所属的微分段ID。微分段ID长度为16bits,同时匹配源、目的微分段所需的ACL资源仅为32bits。对双向流量同时进行管控时,也仅需两条长度为32bits的ACL资源。
微分段技术中使用到以下概念:
· 微分段是一组网络端点的集合,它通过全局唯一的ID来标识。网络管理员可以基于IP地址、IP网段、MAC地址等对网络端点来划分微分段,以便在网络设备上实现基于微分段ID对网络端点进行流量管控。
· GBP(Group Based Policy,组策略)是基于微分段的流量控制策略。通过部署GBP,可以对属于不同微分段的网络端点之间的通信进行安全管控,相同微分段内的网络端点则可以互访,GBP不控制相同微分段内的流量。GBP可以通过报文过滤、QoS策略(MQC)或策略路由实现。
微分段是一种源端控制策略,即在源端设备上配置微分段功能,实现对流量的安全管控。
微分段功能由三部分组成:
(1) 将网络端点加入微分段。根据应用场景和部署方式的不同,可以通过如下方式将网络端点加入微分段:静态IP微分段、静态AC微分段、认证授权微分段和路由通告微分段。
(2) 创建基于微分段ID的ACL。
(3) 使用GBP,即通过报文过滤、QoS策略(MQC)或策略路由引用基于微分段ID的ACL,实现对属于不同微分段的网络端点之间的通信进行安全管控。
在源端设备上完成上述配置,源端设备接收到报文后,根据报文所属的微分段ID,查找匹配的ACL规则,再通过ACL关联到GBP。GBP对命中ACL的报文进行流量控制。
综上所述,微分段是生效在报文转发路径中的源端设备上的。当GBP判决结果为丢弃时,报文将被直接丢弃,不会再经由中间网络转发至目的端,这就避免了带宽浪费。
图36 源端流量控制示意图
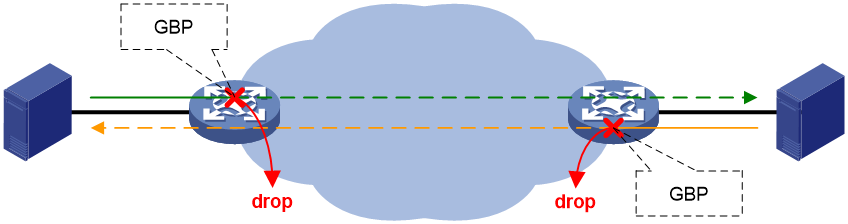
微分段可以应用在EVPN VXLAN数据中心网络中。通过命令行手工部署或SDN控制器自动部署微分段、ACL和GBP。
· 对东西向的流量进行管控时,微分段成员的部署方式为:
在所有Leaf上为VM的IP地址配置全网统一的静态IP微分段。
在Leaf 1和Leaf 2上都配置:
¡ 微分段1成员为192:168:1::0/120。
¡ 微分段2成员为192:168:2::0/120。
¡ 微分段3成员为192:168:3::0/120。
· 对南北向的流量进行管控时,微分段成员的部署方式为:
Border上存在到达Internet和防火墙的静态缺省路由和OA(办公自动化)网络(即192:168:20::0/120)的网段路由,通过BGP将该路由通告给所有Leaf,以实现数据中心通过Border与外部通信。
为了实现南北向流量管控,需要在所有Leaf上配置全网统一的静态IP微分段:
¡ 由于Border会通告缺省路由,所以在Leaf 1和Leaf 2上均配置微分段4,成员为0::0/0。
¡ 由于Border会通告网段路由,所以Leaf 1和Leaf 2上均配置微分段5,成员为192:168:20::0/120。
ACL和GBP则按需配置,允许或禁止各微分段间互访的流量通过。
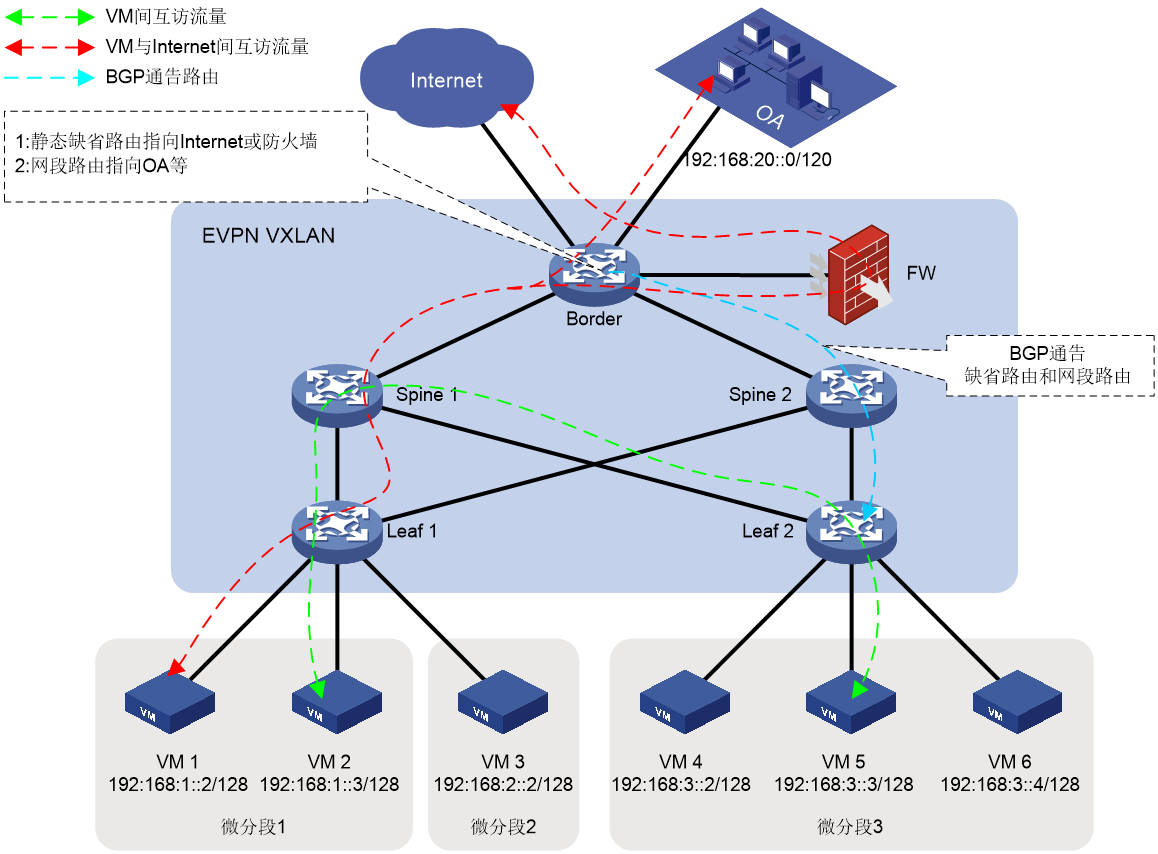
VXLAN(Virtual eXtensible LAN,可扩展虚拟局域网络)是基于IP网络、采用“MAC in UDP”封装形式的二层VPN技术。VXLAN需要手工建立VXLAN隧道。
EVPN(Ethernet Virtual Private Network,以太网虚拟专用网络) VXLAN是一种二层VPN技术,控制平面采用MP-BGP通告EVPN路由信息,数据平面采用VXLAN封装方式转发报文。EVPN VXLAN通过EVPN路由自动建立VXLAN隧道。
VXLAN/EVPN VXLAN可以基于已有的服务提供商或企业IP网络,为分散的站点网络提供二层互联,实现不同租户的业务隔离。通过网关功能,还可以实现站点网络之间的三层互联。
VXLAN/EVPN VXLAN技术将已有的三层物理网络作为Underlay网络,在其上构建出虚拟的二层网络,即Overlay网络。Overlay网络通过封装技术、利用Underlay网络提供的三层转发路径,实现租户二层报文跨越三层网络在不同站点间传递。对于租户来说,Underlay网络是透明的,同一租户的不同站点就像工作在一个局域网中。
站点网络和Underlay网络均可以是IPv6网络。
图38 VXLAN/EVPN VXLAN网络模型示意图
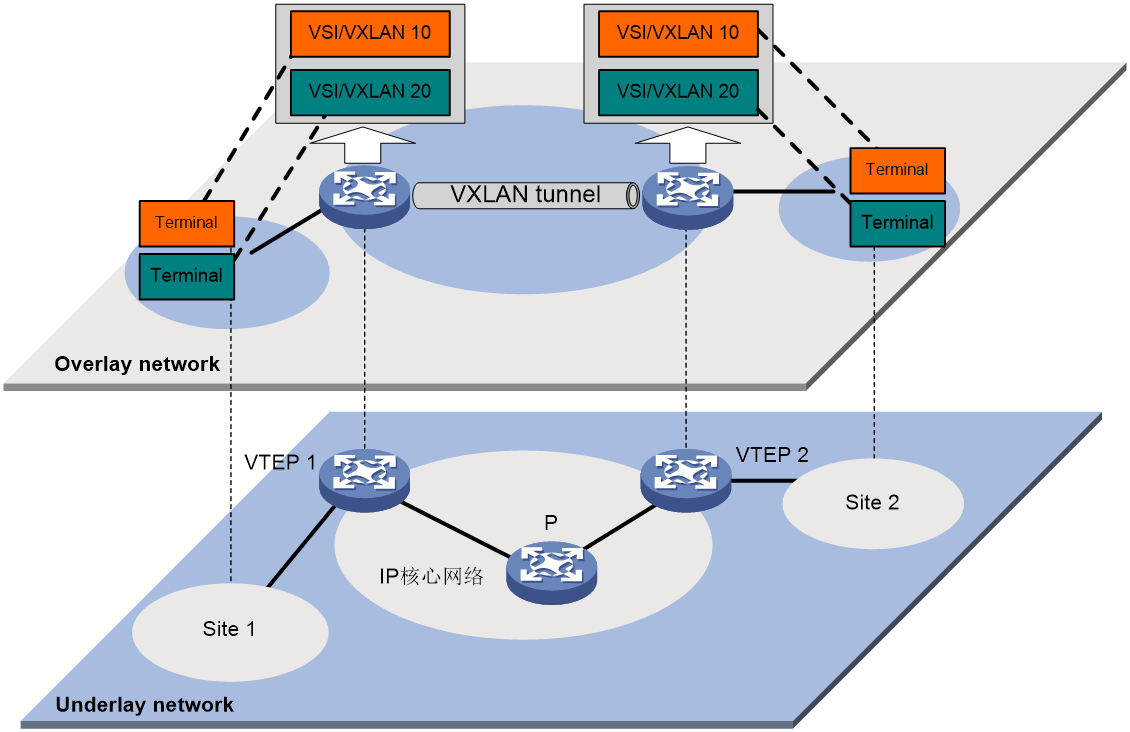
如图38所示,VXLAN/EVPN VXLAN的典型网络模型中包括如下几部分:
· 用户终端(Terminal):用户终端设备可以是PC机、无线终端设备、服务器上创建的VM(Virtual Machine,虚拟机)等。不同的用户终端可以属于不同的VXLAN。属于相同VXLAN的用户终端处于同一个逻辑二层网络,彼此之间二层互通;属于不同VXLAN的用户终端之间二层隔离。VXLAN通过VXLAN ID来标识,VXLAN ID又称VNI(VXLAN Network Identifier,VXLAN网络标识符),其长度为24比特。
· VTEP(VXLAN Tunnel End Point,VXLAN隧道端点):VXLAN的边缘设备。VXLAN的相关处理都在VTEP上进行,例如识别以太网数据帧所属的VXLAN、基于VXLAN对数据帧进行二层转发、封装/解封装报文等。
· VXLAN隧道:两个VTEP之间的点到点逻辑隧道。VTEP为数据帧封装VXLAN头、UDP头和IP头后,通过VXLAN隧道将封装后的报文转发给远端VTEP,远端VTEP对其进行解封装。
· 核心设备:IP核心网络中的设备(如图38中的P设备)。核心设备不参与VXLAN处理,仅需要根据封装后报文的目的IP地址对报文进行三层转发。
· VSI(Virtual Switch Instance,虚拟交换实例):VTEP上为一个VXLAN提供二层交换服务的虚拟交换实例。VSI可以看作VTEP上的一台基于VXLAN进行二层转发的虚拟交换机,它具有传统以太网交换机的所有功能,包括源MAC地址学习、MAC地址老化、泛洪等。VSI与VXLAN一一对应。
· AC(Attachment Circuit,接入电路):VTEP连接本地站点的物理电路或虚拟电路。在VTEP上,与VSI关联的三层接口或以太网服务实例(service instance)称为AC。其中,以太网服务实例在二层以太网接口上创建,它定义了一系列匹配规则,用来匹配从该二层以太网接口上接收到的数据帧。
IPv6网络的部署不是一蹴而就的,在一段时间内IPv4网络会与IPv6网络共存。过渡技术用来解决IPv4网络与IPv6网络共存和互通的问题。常用的过渡技术包括双栈、隧道、协议转换(AFT)和6PE。
双栈技术是一种最简单直接的过渡机制。双栈技术是指网络中的节点同时支持IPv4和IPv6两个协议栈,这样的节点称为双协议栈节点。当双协议栈节点配置IPv4地址和IPv6地址后,就可以在相应接口上转发IPv4和IPv6报文。当一个上层应用同时支持IPv4和IPv6协议时,根据协议要求可以选用TCP或UDP作为传输层的协议,但在选择网络层协议时,它会优先选择IPv6协议栈。
双栈技术是所有过渡技术的基础。双栈技术具有如下优点:
· 技术成熟,不必为不同类型的用户单独部署网络配置。
· 开销相对较小,保护用户投资。
· 过渡平滑,通过IPv6优选逐步提高IPv6流量占比。
· 实现快速业务互访,互通性好,降低了跨协议访问时的地址转换损耗。
双栈技术的缺点为:
· 改造工作量大,需完成整网的IPv4和IPv6部署,配置管理也较为复杂。
· 设备性能要求高,需考虑设备硬件资源表项共享问题。
· 要求双协议栈节点拥有一个全球唯一的IPv4地址和IPv6地址,实际上没有解决IPv4地址资源匮乏的问题。
隧道是一种封装技术,它利用一种网络协议来传输另一种网络协议,即利用一种网络传输协议,将其他协议产生的数据报文封装在它自己的报文中,然后在网络中传输。
IPv6 over IPv4隧道和IPv4 over IPv6隧道可以用于连接IPv6或IPv4的信息孤岛,解决IPv4网络与IPv6网络共存问题:
· IPv6 over IPv4隧道:如图39所示,将IPv6报文封装到IPv4报文中,实现IPv6节点跨越IPv4网络进行互通。IPv6 over IPv4隧道包括IPv6 over IPv4手动隧道、IPv4兼容IPv6自动隧道、6to4隧道、ISATAP隧道和6RD隧道。
图39 IPv6 over IPv4隧道示意图
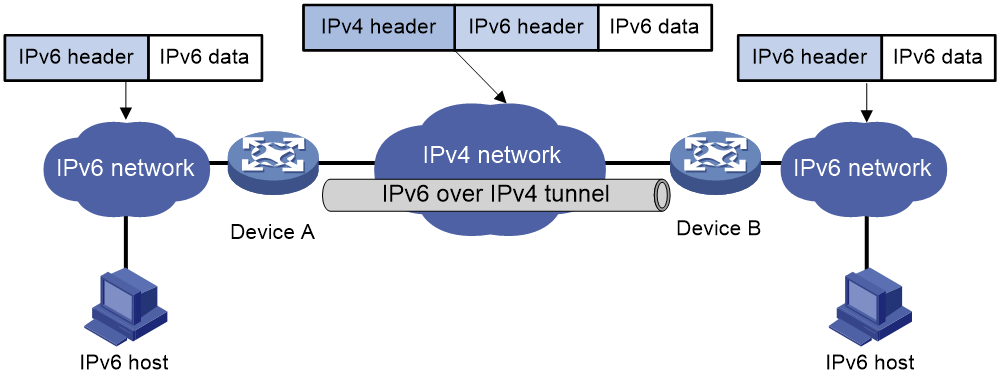
· IPv4 over IPv6隧道:如图40所示,将IPv4报文封装到IPv6报文中,实现IPv4节点跨越IPv6网络进行互通。
图40 IPv4 over IPv6隧道示意图
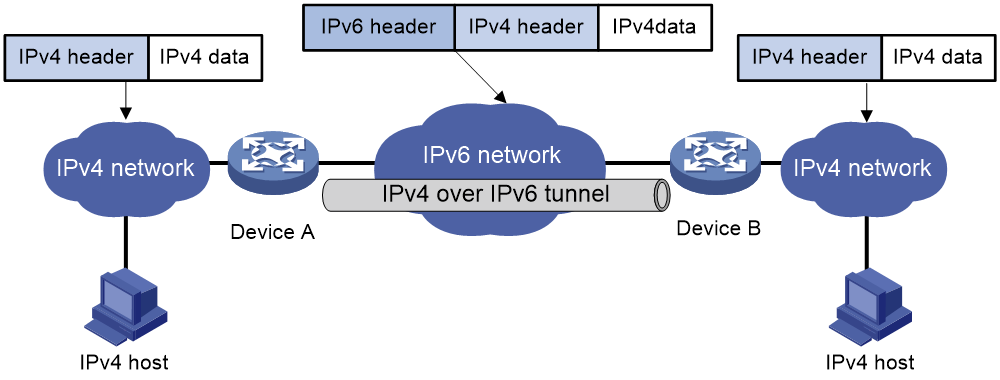
隧道技术可以实现不同数据中心网络、不同站点网络穿越骨干网互通,互通过程对于骨干网来说是透明的,多用于广域网。
隧道技术的优点为:
· 原有网络拓扑和路由几乎无需调整,可以短期内快速实现少量IPv6站点间的业务互访。
· 仅需对IPv4和IPv6网络的边界设备进行升级,改造范围小,成本低,且技术比较成熟。
隧道技术的缺点为:
· 无法实现跨协议的应用互访,需与协议转换技术配合使用。
· 隧道技术为软件功能实现,大规模组网时需消耗设备CPU、内存等资源,设备性能成为瓶颈。
· 运维工作量大,界面不清晰,不推荐大规模部署。
AFT(Address Family Translation,地址族转换)提供了IPv4和IPv6地址之间的相互转换功能,使IPv4网络和IPv6网络可以直接通信。
AFT作用于IPv4和IPv6网络边缘设备上,所有的地址转换过程都在该设备上实现,对IPv4和IPv6网络内的用户来说是透明的,即用户不必改变目前网络中主机的配置就可实现IPv6网络与IPv4网络的通信。
节点不具备升级IPv6能力时,在IPv4与IPv6网络边界点增加协议转换设备,可以快速实现IPv4/IPv6节点的跨协议互访。
AFT支持三种前缀转换方式,包括NAT64前缀转换、IVI前缀转换和General前缀转换。
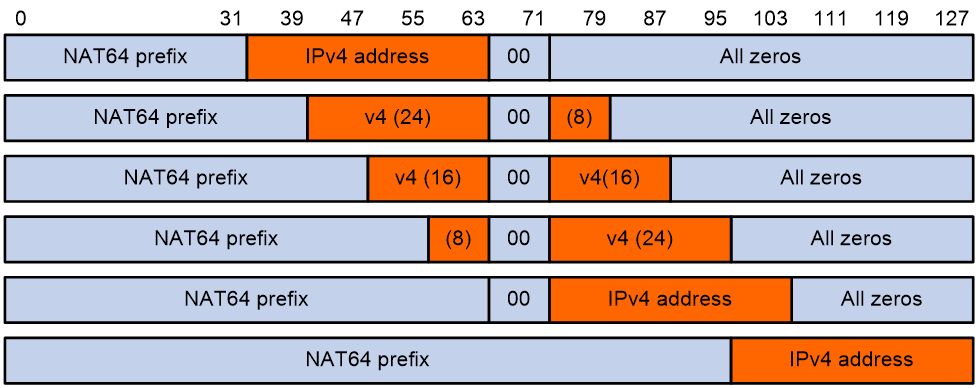
NAT64前缀是长度为32、40、48、56、64或96位的IPv6地址前缀,用来构造IPv4节点在IPv6网络中的地址,以便IPv4主机与IPv6主机通信。网络中并不存在带有NAT64前缀的IPv6地址的主机。
如图41所示,NAT64前缀长度不同时,地址转换方法有所不同。其中,NAT64前缀长度为32、64和96位时,IPv4地址作为一个整体添加到IPv6地址中;NAT64前缀长度为40、48和56位时,IPv4地址被拆分成两部分,分别添加到64~71位的前后。64~71位为保留位,必须设置为0。
图41 对应IPv4地址带有NAT64前缀的IPv6地址格式
AFT构造IPv4节点在IPv6网络中的地址示例如表9所示。
表9 IPv4地址带有NAT64前缀的IPv6地址示例
|
IPv6前缀 |
IPv4地址 |
嵌入IPv4地址的IPv6地址 |
|
2001:db8::/32 |
192.0.2.33 |
2001:db8:c000:221:: |
|
2001:db8:100::/40 |
192.0.2.33 |
2001:db8:1c0:2:21:: |
|
2001:db8:122::/48 |
192.0.2.33 |
2001:db8:122:c000:2:2100:: |
|
2001:db8:122:300::/56 |
192.0.2.33 |
2001:db8:122:3c0:0:221:: |
|
2001:db8:122:344::/64 |
192.0.2.33 |
2001:db8:122:344:c0:2:2100:: |
|
2001:db8:122:344::/96 |
192.0.2.33 |
2001:db8:122:344::192.0.2.33 |
IVI前缀是长度为32位的IPv6地址前缀。IVI地址是IPv6主机实际使用的IPv6地址,这个IPv6地址中内嵌了一个IPv4地址,可以用于与IPv4主机通信。由IVI前缀构成的IVI地址格式如图42所示。
图42 IVI地址格式
![]()
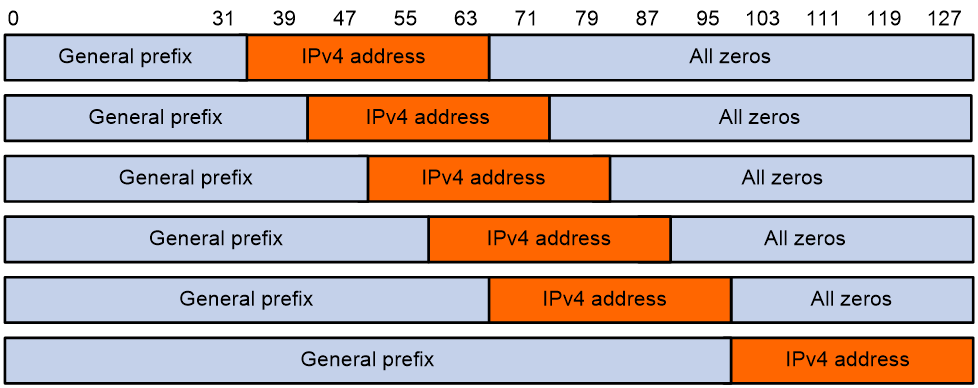
General前缀与NAT64前缀类似,都是长度为32、40、48、56、64或96位的IPv6地址前缀,用来构造IPv4节点在IPv6网络中的地址。如图43所示,General前缀与NAT64前缀的区别在于,General前缀没有64到71位的8位保留位,IPv4地址作为一个整体添加到IPv6地址中。
图43 对应IPv4地址带有General前缀的IPv6地址格式
AFT的优点为:
· 仅需要升级IPv4和IPv6网络边缘设备,改造范围小,短期内可以快速完成IPv4向IPv6升级改造。
· 业务系统无需做IPv6改造升级。
AFT的缺点为:
· AFT与业务强耦合,对于部分协议,不仅要对报文头中的源和目的地址进行转换,还需要与ALG(Application Level Gateway,应用层网关)协同工作,识别出应用层数据载荷中的地址信息并进行地址转换,增加了处理的复杂度。并且,协议转换时,可能造成协议信息的丢失。
· 破坏了Internet节点的对等性。
· 溯源困难。
如图44所示,6PE(IPv6 Provider Edge,IPv6供应商边缘)是一种过渡技术,它采用MPLS(Multiprotocol Label Switching,多协议标签交换)技术实现通过IPv4骨干网连接隔离的IPv6用户网络。当ISP希望在自己原有的IPv4/MPLS骨干网的基础上,为用户网络提供IPv6流量转发能力时,可以采用6PE技术方便地达到该目的。
图44 6PE组网图
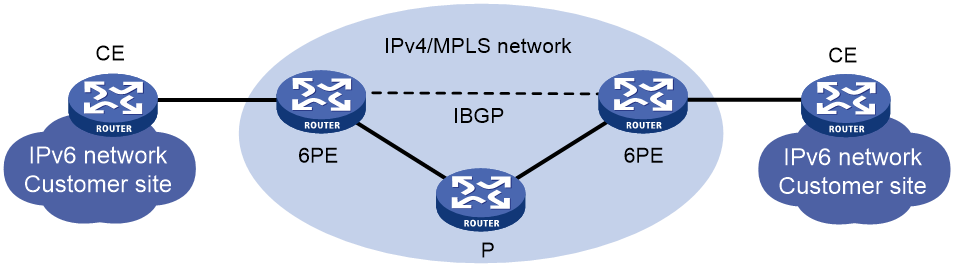
6PE的主要思想是:
· 6PE设备从CE(Customer Edge,用户网络边缘)设备接收到用户网络的IPv6路由信息后,为该路由信息分配标签,通过MP-BGP会话将带有标签的IPv6路由信息发布给对端的6PE设备。对端6PE设备将接收到的IPv6路由信息扩散到本地连接的用户网络。从而,实现IPv6用户网络之间的路由信息发布。
· 为了隐藏IPv6报文、使得IPv4骨干网中的设备能够转发IPv6用户网络的报文,在IPv4骨干网络中需要建立公网隧道。公网隧道可以是GRE隧道、MPLS LSP、MPLS TE隧道等。
· 6PE设备转发IPv6报文时,先为IPv6报文封装IPv6路由信息对应的标签(内层标签),再为其封装公网隧道对应的标签(外层标签)。骨干网中的设备根据外层标签转发报文,意识不到该报文为IPv6报文。对端6PE设备接收到报文后,删除内层和外层标签,将原始的IPv6报文转发到本地连接的用户网络。
借助6PE技术,IPv4网络运营商仅需对IPv4和IPv6网络的边界设备进行升级,使其支持IPv4/IPv6双协议栈,就可利用自己原有的IPv4/MPLS网络为分散的IPv6孤岛用户提供接入能力。6PE技术的优点是部署所需的改造范围小,但缺点是配置复杂,不利于后续进行维护。
6vPE即IPv6 MPLS L3VPN,其典型组网环境如图45所示。6vPE组网中,服务提供商骨干网为IPv4网络。VPN内部及CE和PE之间运行IPv6协议,骨干网中PE和P设备之间运行IPv4协议。PE需要同时支持IPv4和IPv6协议,连接CE的接口上使用IPv6协议,连接骨干网的接口上使用IPv4协议。PE从CE接收到IPv6路由后,为其分配私网标签,并通过VPNv6路由将私网标签和IPv6路由信息发布给远端PE。PE通过IPv4骨干网转发IPv6报文时,为IPv6报文封装私网标签,以实现在IPv4网络上透明传输IPv6报文,达到IPv6网络通过IPv4网络互通的目的。
图45 IPv6 MPLS L3VPN应用组网图
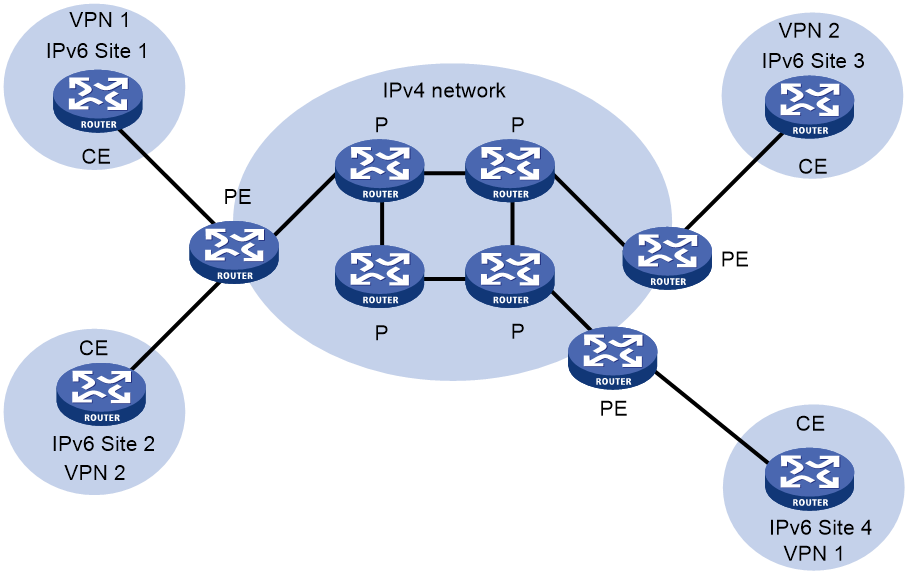
图46 IPv6 MPLS L3VPN报文转发示意图
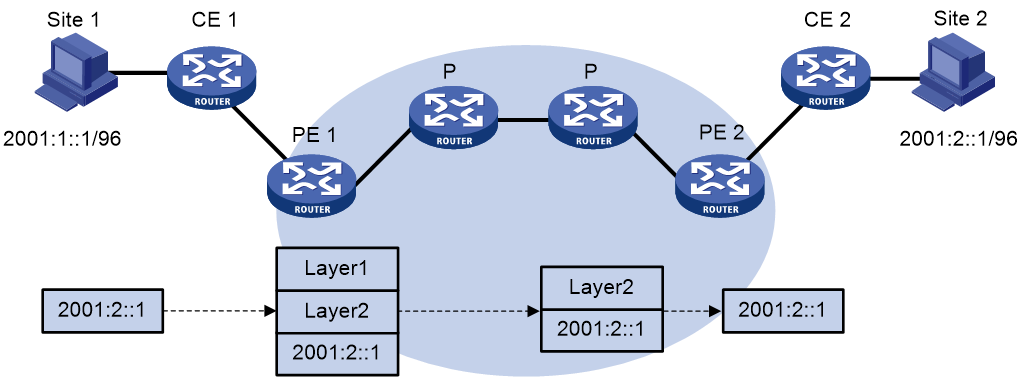
如图46所示,IPv6 MPLS L3VPN的报文转发过程为:
(1) Site 1发出一个目的地址为2001:2::1的IPv6报文,由CE 1将报文发送至PE 1。
(2) PE 1根据报文到达的接口及目的地址查找VPN实例的路由表项,匹配后将报文转发出去,同时打上公网和私网两层标签。
(3) MPLS网络利用报文的外层标签,将报文传送到PE 2。(报文在到达PE 2前一跳时已经被剥离外层标签,到达PE 2时仅含内层标签)
(4) PE 2根据内层标签和目的地址查找VPN实例的路由表项,确定报文的出接口,将报文转发至CE 2。
(5) CE 2根据正常的IPv6转发过程将报文传送到目的地。
6vPE用来通过IPv4网络连接孤立的IPv6站点,要求骨干网络支持MPLS L3VPN,部署负责,不利于后期维护。
IPv6+是面向5G和云时代的智能IP技术。IPv6+对IPv6协议进行了创新,在IPv6协议基础上增加了智能识别与控制,具有可编程路径、快速业务发放、自动化运维、质量可视化、SLA保障和应用感知等特点。
IPv6+技术创新体系的发展分为三个阶段:
· IPv6+1.0:主要为SRv6基础特性,包括TE、VPN、FRR等目前广泛应用的特性。
· IPv6+2.0:针对5G与云时代的新业务与新功能需求,进一步进行一系列的技术创新,包含但不局限于iFIT、BIER、网络切片、G-SRv6、SFC(service function chaining,业务链)、DetNet确定性网络等。
· IPv6+3.0:重点是APN6(application-aware IPv6 networking,感知应用的IPv6网络)。APN6在“IPv6+”2.0的基础上进一步实现网络能力与业务需求的无缝结合。利用SRv6的路径可编程特点,将应用信息(应用标识、对网络性能的需求等)携带在SRv6报文中,使网络感知到应用及其需求,以便为其提供相应SLA保障。
目前,我司支持的IPv6+协议创新包括SRv6、网络切片、iFIT、BIER:
· SRv6(Segment Routing IPv6,IPv6段路由):新一代网络承载技术。SRv6是IPv6+的关键技术,它通过IPv6扩展头,实现网络路径灵活编排。目前,我司支持SRv6基础特性、G-SRv6和SFC。
· 网络切片:将一个物理网络划分为多个逻辑网络,实现一网多用、业务隔离。
· iFIT(in-situ Flow Information Telemetry):一种直接测量网络性能指标的检测技术,通过gRPC上报检测结果,以实现网络可视化。
· BIER(Bit Index Explicit Replication,位索引显式复制技术):一种新型的组播转发技术架构,实现IPv6组播流量转发的同时,简化了网络协议,并提供了良好的组播业务扩展性。
SRv6是基于IPv6和源路由(Source Routing)的新一代网络承载技术,它简化了传统的复杂网络协议,实现应用级的SLA保障。SRv6具有强大的网络可编程能力,是实现网络自动化的基石。SRv6能够将网络分片的数据面进行统一,既具备IPv6的灵活性和强大的可编程能力,又可以为智能IP网络切片、确定性网络、业务链等应用提供强有力的支撑。
SRv6是指在IPv6网络中使用Segment Routing,将IPv6地址作为SID,SRv6 节点根据SID对报文进行转发。SRv6将SID列表封装在IPv6报文的SRH(Segment Routing Header,SR报文头)中,以控制报文转发路径。
SRv6技术具有如下优势:
· 简化维护
仅需要在源节点上控制和维护路径信息,网络中其他节点不需要维护路径信息。
· 智能控制
SRv6基于SDN架构设计,跨越了应用和网络之间的鸿沟,能够更好地实现应用驱动网络。SRv6中转发路径、转发行为、业务类型均可控。
· 部署简单
SRv6基于IGP和BGP扩展实现,无须使用MPLS标签,不需要部署标签分发协议,配置简单。
在SRv6网络中,不需要大规模升级网络设备,就可以部署新业务。在DC(Data Center,数据中心)和WAN(广域网)中,只需网络边界设备及特定网络节点支持SRv6,其他设备支持IPv6即可。
· 适应5G业务需求
随着5G业务的发展,IPv4地址已经无法满足运营商的网络需求。可通过在运营商网络中部署SRv6,使所有设备通过IPv6地址转发流量,实现IPv6化网络,以满足5G业务需求。
· 易于实现VPN等新业务
SRv6定义了多种类型的SID,不同SID具有不同的作用,指示不同的转发动作。通过不同的SID操作,可以实现VPN等业务处理。
日后,用户还可以根据实际需要,定义新的SID类型,具有很好的扩展性。
如图47所示,将SRv6报文简化,以便于理解SRv6的转发原理,其中:
· IPv6 Destination Address:IPv6报文的目的地址,简称IPv6 DA。在普通IPv6报文里,IPv6 DA是固定不变的。在SRv6中,IPv6 DA仅标识当前报文的下一个节点,是不断变换的。
· SRH(SL=n-1)<Segment List [0]=a, Segment List [1]=b, …, Segment List [n-1]=x>:SRv6报文的SID列表。通过SL和Segment List字段共同决定IPv6 DA的取值。
图47 SRv6报文简化示意图

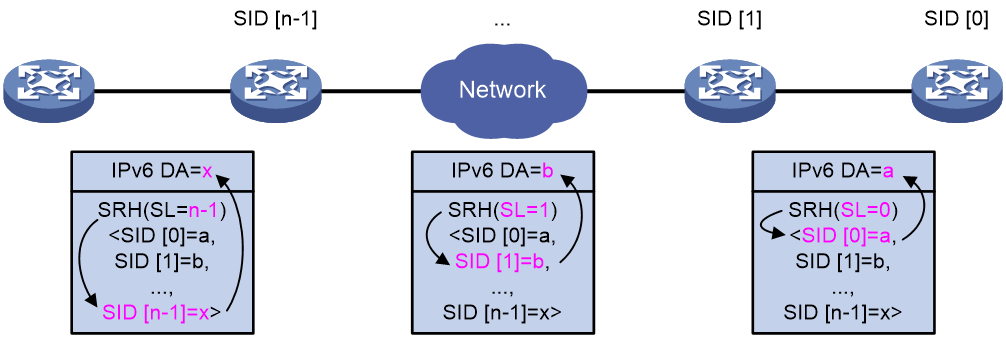
如图48所示,在SRv6中,每经过一个SRv6节点,SL字段减1,IPv6 DA信息变换一次:
· 如果SL=n-1,则IPv6 DA为SID [n-1]=x。
· 如果SL=1,则IPv6 DA为SID [1]=b。
· 如果SL=0,则IPv6 DA为SID [0]=a。
图48 SRH处理过程示意图
SRv6报文支持SRv6 BE和SRv6 TE Policy两种转发方式:
· SRv6 BE(SRv6 Best Effort)是指通过IGP协议发布Locator网段,SRv6网络中的节点按最短路径优先算法计算到达Locator网段的最优路由。该路由对应的路径为SRv6 BE路径。公网BGP路由或者VPN实例的BGP路由迭代到SRv6 BE路径后,可以实现将公网流量或VPN流量引入SRv6 BE路径。
· SRv6 TE Policy是指报文的入口节点通过不同的引流方式,将公网流量或VPN流量引入SRv6 TE Policy转发。SRv6 TE Policy对应的路径为SRv6 TE路径。
在SRv6 TE Policy组网场景中,管理员需要将报文转发路径上的SRv6节点的128-bit SRv6 SID添加到SRv6 TE Policy的SID列表中。因此,路径越长,SRv6 TE Policy的SID列表中SRv6 SID数目越多,SRv6报文头开销也越大,导致设备转发效率低、芯片处理速度慢。在跨越多个AS域的场景中,端到端的SRv6 SID数目可能更多,报文开销问题更加严峻。
Generalized SRv6(G-SRv6)通过对128-bit SRv6 SID进行压缩,在SRH的Segment List中封装更短的SRv6 SID(G-SID),来减少SRv6报文头的开销,从而提高SRv6报文的转发效率。同时,G-SRv6支持将128-bit SRv6 SID和G-SID混合编排到Segment List中。
部署SRv6时,通常会规划出一个地址块,专门用于SRv6 SID的分配,这个地址块称为SID Space。在一个SRv6域中,SRv6 SID均从SID Space中分配,具有相同的前缀(即公共前缀Common Prefix)。因此,Segment List中SRv6 SID的公共前缀是冗余信息。G-SRv6将Segment List中SRv6 SID的Common Prefix移除,仅携带SRv6 SID中的可变部分,即压缩SID(G-SID),可以有效减少SRv6报文头开销。报文转发过程中,在根据SRH头中的Segment List替换报文的目的地址时,将G-SID与Common Prefix拼接形成新的目的地址,继续查表转发。
G-SRv6对SRv6 SID进行压缩时,既要保证高效压缩,又要兼顾网络规模等需求。综合考虑,32比特是当前较为理想的压缩后SID长度。
如图49所示,SRv6 SID的Locator部分可以细分为Common Prefix和Node ID,其中Common Prefix表示公共前缀地址;Node ID表示节点标识。具有相同Common Prefix的SRv6 SID可以进行压缩,形成32-bit G-SID。32-bit G-SID由128-bit SRv6 SID中的Node ID和Function组成。128-bit SRv6 SID和32-bit G-SID的转换关系为:128-bit SRv6 SID = Common Prefix + 32-bit G-SID + 0 (Args&MBZ)
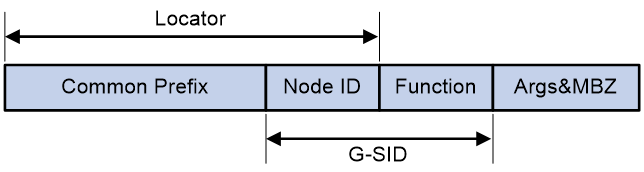
图50 G-SRv6报文格式示意图

![]()
如果下一个节点的SRv6 SID需要进行压缩,则路由协议在发布本节点的SRv6 SID时,会为该SRv6 SID添加COC标记,标识本SRv6 SID之后是G-SID。 报文中不会携带COC标记,COC是SRv6 SID本身的转发行为,为了方便理解,在报文结构中标识出SRv6 SID是否具有COC标记。
如图50所示,G-SRv6可以将G-SID和128-bit SRv6 SID混合编排在SRH的Segment List中。为准确定位G-SID,需要在原本封装128-bit SRv6 SID的位置封装4个32-bit G-SID。如果封装的G-SID不足4个,即不足128比特,则需要用0补齐,对齐128比特。128比特中封装的G-SID称为一组G-SID。多个连续的G-SID组成一段压缩路径,称为G-SID List。G-SID List中可以包含一组或多组G-SID。
G-SID在Segment List中的排列规则为:
(2) G-SID List的前一个SRv6 SID为携带COC标记的128-bit SRv6 SID,标识下一个SID为32-bit G-SID。
(3) 除G-SID List中的最后一个G-SID外,其余G-SID必须携带COC标记,标识下一个SID为32-bit G-SID。
(4) G-SID List的最后一个G-SID必须是未携带COC标记的32-bit G-SID,标识下一个SID为128-bit SRv6 SID。
(5) G-SID List结束的下一个SRv6 SID为128-bit SRv6 SID,其可以是未携带COC标记的SRv6 SID,也可以是携带COC标记的SRv6 SID。
图51 G-SID组成示意图

如图51所示,使用G-SID计算目的地址的方法为将Segment List中的G-SID与Common Prefix拼接形成新的目的地址。其中:
· Common Prefix:公共前缀,由管理员手工配置。
· G-SID:按照32比特进行压缩的SID,从SRH中获取。
· SI(SID Index):用于在一组G-SID中定位G-SID。SI为目的地址的最低两位,取值为0~3。每经过一个对SID进行压缩的节点,SI值减1。如果SI值为0,则将SL值减1。在Segment List的一组G-SID中,G-SID按照SI从小到大的顺序从左到右依次排列,即最左侧的G-SID的SI为0,最右侧的G-SID的SI为3。
· 0:若Common Prefix、G-SID和SI的位数之和不足128比特,则中间位使用0补齐。
如果SRv6节点上管理员部署的Common Prefix为A:0:0:0::/64、SRv6报文中的当前的G-SID为1:1,该G-SID对应的SI为3,则组合成的目的地址为A:0:0:0:1:1::3。
SRv6节点收到G-SRv6报文后,不同情况下,报文目的地址计算方法为:
· 如果当前报文的目的地址在Segment List中为携带COC标记的128-bit SRv6 SID,则表示下一个SID为G-SID,将SL-1,根据[SL-1]值定位所处的G-SID组,并按照上述方法根据[SI=3]对应的32-bit G-SID计算目的地址。
· 如果当前报文的目的地址在Segment List中为携带COC标记的32-bit G-SID,则表示下一个SID为G-SID:
¡ 如果SI>0,则将SI-1,根据报文当前的SL值定位所处的G-SID组,并按照上述方法根据[SI-1]对应的32-bit G-SID计算目的地址。
¡ 如果SI=0,则将SL-1、将SI值重置,即将SI设置为3,根据报文当前的SL值定位所处的G-SID组,并按照上述方法根据[SI=3]对应的32-bit G-SID计算目的地址。
· 如果当前报文的目的址在Segment List中是未携带COC标记的32-bit G-SID,则将SL-1,同时查找[SL-1]对应的128-bit SRv6 SID,并使用该SRv6 SID替换IPv6头中的目的地址。
· 如果当前报文的目的址在Segment List中是未携带COC标记的128-bit SRv6 SID,则将SL-1,同时查找[SL-1]对应的128-bit SRv6 SID,并使用该SRv6 SID替换IPv6头中的目的地址。
为了保证SD-WAN网络中业务流量的稳定,SRv6提供了高可靠性措施,避免业务流量长时间中断,提高网络质量。
SRv6提供以下功能保证网络的可靠性:
· TI-LFA FRR(Topology-Independent Loop-free Alternate,拓扑无关无环备份快速重路由):高保护率的FRR保护能力,TI-LFA FRR原理上支持任意拓扑保护,能够弥补传统隧道保护技术的不足。
· SRv6防微环:解决全互联组网中IGP协议在无序收敛时产生的环路,支持正切防微环和回切防微环,消除微环导致的网络丢包、时延抖动和报文乱序等一系列问题。
· 中间节点保护:解决SRv6 TE Policy场景由于严格节点约束导致的TI-LFA FRR保护失效问题。
· 尾节点保护:在双归接入场景中,解决SRv6 TE Policy的尾节点发生单点故障,引起的报文转发失败问题。
传统VPN网络中通过部署LDP/RSVP-TE等标签分发协议,在公网中建立虚拟专用通信网络。这种方式部署复杂,维护成本较高。通过在公网部署SRv6 VPN可以解决上述问题。SRv6 VPN是通过SRv6隧道承载IPv6网络中的VPN业务的技术,控制平面采用MP-BGP通告VPN路由信息,数据平面采用SRv6封装方式转发报文。租户的物理站点分散在不同位置时,SRv6 VPN可以基于已有的服务提供商或企业IP网络,为同一租户的不同物理站点提供二层或三层互联。
根据VPN业务种类,SRv6 VPN分为:
· L3VPN业务:IP L3VPN over SRv6和EVPN L3VPN over SRv6
· L2VPN业务:EVPN VPWS over SRv6和EVPN VPLS over SRv6
如图52所示,IP L3VPN over SRv6通过MP-BGP在IPv6骨干网上发布用户站点的IPv4/IPv6私网路由,使用PE间的SRv6路径承载私网报文,从而实现通过IPv6骨干网连接属于同一个VPN、位于不同地理位置的用户。
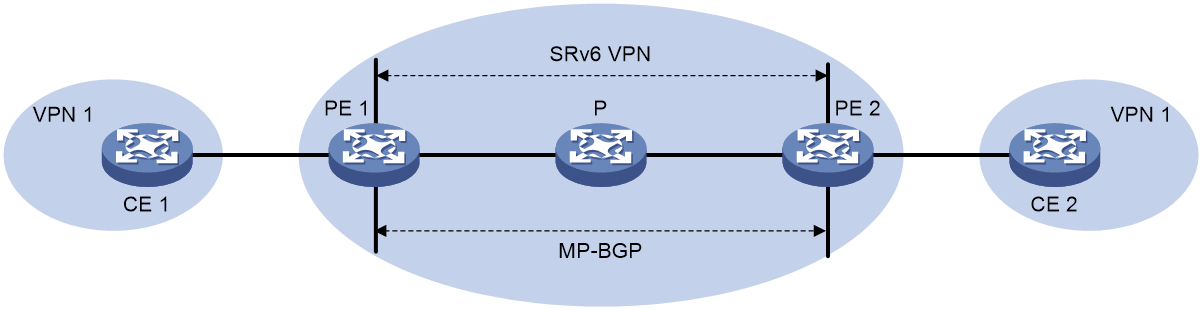
如图53所示,EVPN L3VPN over SRv6通过MP-BGP在IPv6骨干网上使用EVPN的IP前缀路由发布用户站点的IPv4/IPv6私网路由,使用PE间的SRv6路径承载私网报文,从而实现通过IPv6骨干网连接属于同一个VPN、位于不同地理位置的用户。
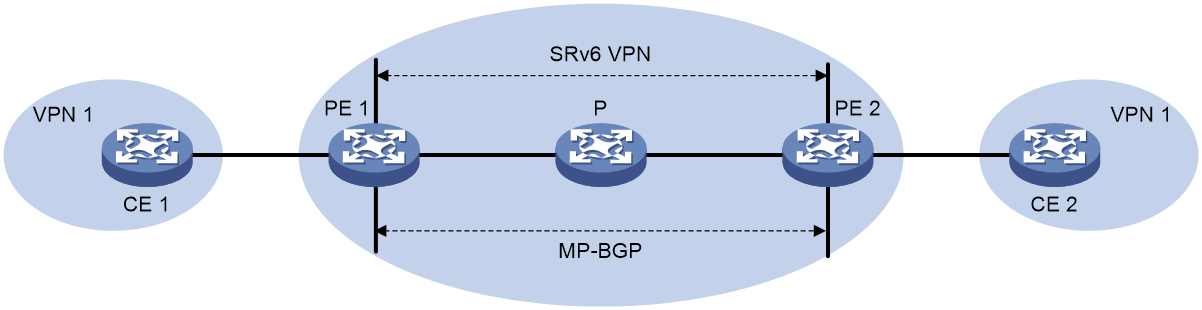
EVPN VPWS over SRv6是指通过SRv6隧道承载EVPN VPWS业务,通过IPv6网络透明传输用户二层数据,实现用户网络穿越IPv6网络建立点到点连接。
如图54所示,PE之间通过EVPN路由发布SRv6 SID,建立SRv6隧道。该SRv6隧道作为PW,封装并转发站点网络之间的二层数据报文。
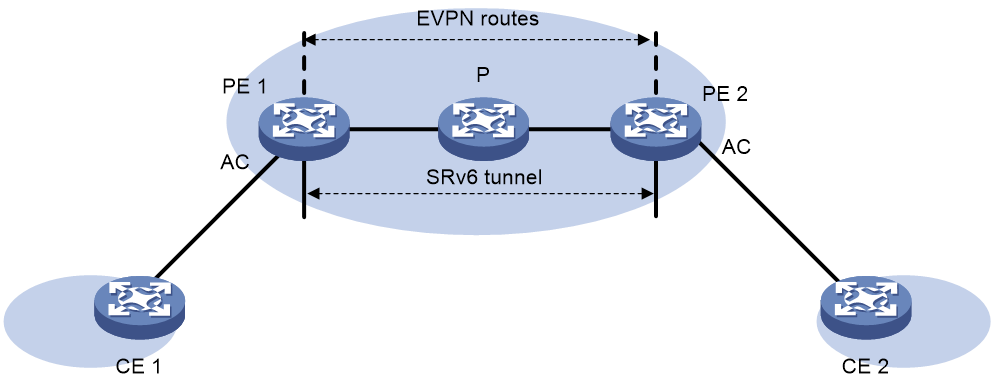
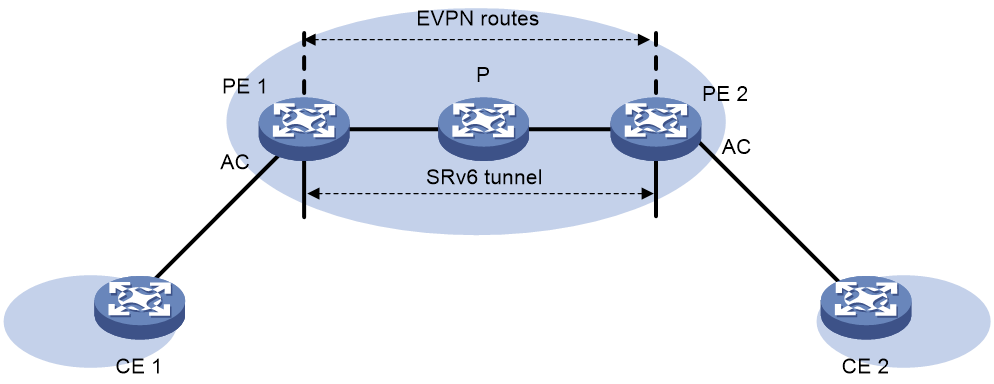
EVPN VPLS over SRv6是指通过SRv6隧道承载EVPN VPLS业务,通过IPv6网络透明传输用户二层数据,实现用户网络穿越IPv6网络建立点到多点连接。
如图55所示,PE之间通过EVPN路由发布SRv6 SID,建立SRv6隧道。该SRv6隧道作为PW,封装并转发站点网络之间的二层数据报文。
如图56所示,公网IP over SRv6通过MP-BGP在IPv6骨干网上发布用户站点的IPv4/IPv6路由,使用PE间的SRv6路径承载用户报文,从而实现通过IPv6骨干网连接位于不同地理位置的用户。
图56 公网IP over SRv6组网示意图

网络切片是指在同一个物理网络的基础上,网络管理员通过各种切片技术为特定业务或用户上划分出多个逻辑网络,即切片网络。每个切片网络都有自己的网络拓扑、SLA(Service Level Agreement)需求、安全和可靠性要求。切片网络最大化地利用现网的网络设施资源,为不同业务、行业或用户提供差异化网络服务。
网络切片的价值体现在如下几个方面:
· 满足差异化SLA需求:对于运营商或者大型企业而言,当前不同业务通过一张网络承载,不断涌现的新业务对这张网络提出了差异化SLA的需求,例如自动驾驶业务对时延,抖动的要求十分严格,但带宽需求不大,而VR和高清视频等业务又对网络带宽需求极大,对时延并无特殊需求。传统的物理网络无法满足差异化SLA要求,而建设独立的专网成本过高,部署网络切片方案为不同业务按需提供不同切片网络可以满足上述需求。
· 满足网络资源隔离的需求:一些行业用户需要安全可靠且独享的网络资源,运营商也希望为不同等级的用户提供安全隔离措施,避免部分普通客户抢占网络资源,造成其他优质用户体验下降问题,网络切片方案可以在数据平面、控制平面和管理层面为不同用户分配不同资源。
· 满足灵活定制拓扑的需求:随着云网融合技术的发展,虚拟机可以跨数据中心随时迁移,网络的连接关系更加灵活复杂,网络切片方案中通过部署Flex-Algo技术满足网络拓扑灵活动态的变化需求。
网络切片并非特指某一种网络技术,而是利用多种网络技术实现的一整套解决方案。为了实现在物理网络上划分逻辑网络的功能,满足不同用户和业务的资源隔离、差异化SLA以及灵活拓扑的需求,网络切片方案中包含但不限于表10中所列的技术。
|
技术名称 |
实现层级 |
说明 |
|
MDC |
· 管理平面 · 控制平面 · 数据平面 |
通过虚拟化技术将一台物理设备划分成多台逻辑设备,每台逻辑设备就称为一台MDC(Multitenant Device Context,多租户设备环境)。 每台MDC拥有自己专属的软硬件资源,独立运行,独立转发,独立提供业务。对于用户来说,每台MDC就是一台独立的物理设备。MDC之间相互隔离,不能直接通信,具有很高的安全性。 |
|
Flex-Algo |
控制平面 |
Flex-Algo(Flexible Algorithm,灵活算法)是一种在IGP协议基础上运行的灵活算法,它允许用户自定义IGP路径算法的度量类型,例如Cost开销、链路时延值或TE度量值,利用SPF算法计算到达目的地址的最短路径。 计算最短路径时,Flex-Algo还允许用户使用的链路的亲和属性和SRLG(Shared Risk Link Group,共享风险链路组)作为约束条件来限制最终拓扑必须包含或排除某些链路。 因此,参与不同Flex-Algo算法的网元可以组成多个独立的逻辑拓扑,物理网络中部署多个Flex-Algo算法可以按需划分成多个独立的网络切片。 |
|
FlexE |
数据平面 |
FlexE(Flexible Ethernet,灵活的以太网)技术基于高速以太网接口,通过以太网MAC速率和PHY速率的解耦,实现灵活控制接口速率。 FlexE通过一个或捆绑多个IEEE 802.3标准的高速物理接口提供大带宽,再根据业务带宽需求,将上述物理接口的总带宽灵活分配给各FlexE业务接口。每一个FlexE业务接口就可以为切片网络转发数据。 |
|
子接口切片 |
数据平面 |
子接口切片是一种小粒度的网络切片技术。通过在高速率端口上创建子接口,并为这些子接口配置子接口切片带宽,利用接口的队列资源,实现子接口上数据转发的隔离。这些配置了子接口切片带宽的子接口称为切片子接口。切片子接口独享为其分配的带宽,并使用独立的队列进行调度。 |
|
Slice ID切片 |
数据平面 |
基于Slice ID的网络切片是一种应用在SRv6组网场景中的网络切片技术方案,它通过全局唯一的Slice ID来标识和划分切片网络。 在切片网络中转发的业务报文将携带Slice ID,设备转发该报文时先查询FIB表找到出接口,再根据Slice ID从对应出接口上切片通道转发报文。 |
采用Slice ID切片技术的网络切片方案因为支持的切片数量多(可达千级),配置实现简单,转发接口所需SRv6 SID少(所有网络切片仅需一套SRv6 Locator资源)等优势成为网络切片当前推荐方案。下面仅以基于Slice ID的网络切片方案为例,介绍网络切片的基本原理。
Slice ID是实现网络切片的关键:
· 本方案通过在设备上配置全局唯一的Slice ID来创建切片实例,即虚拟设备,实现物理设备到切片网络中的映射;
· 在设备接口上的配置Slice ID来创建不同切片网络使用的的数据转发通道,并为该数据通道分配独享带宽资源;
· 最后,由同一Slice ID来标识的虚拟设备和数据转发通道组成切片网络。
在数据转发过程中,网络切片里转发的报文也必须携带Slice ID。同时SRv6 TE Policy需要与Slice ID关联。SRv6 TE Policy可以通过如下方法与Slice ID关联:
· 通过配置手工指定。
· 从对等体发布的BGP IPv6 SR Policy路由中学习。
以L3VPNv4 over SRv6 TE Policy组网为例,介绍基于Slice ID的网络切片方案的报文转发过程。
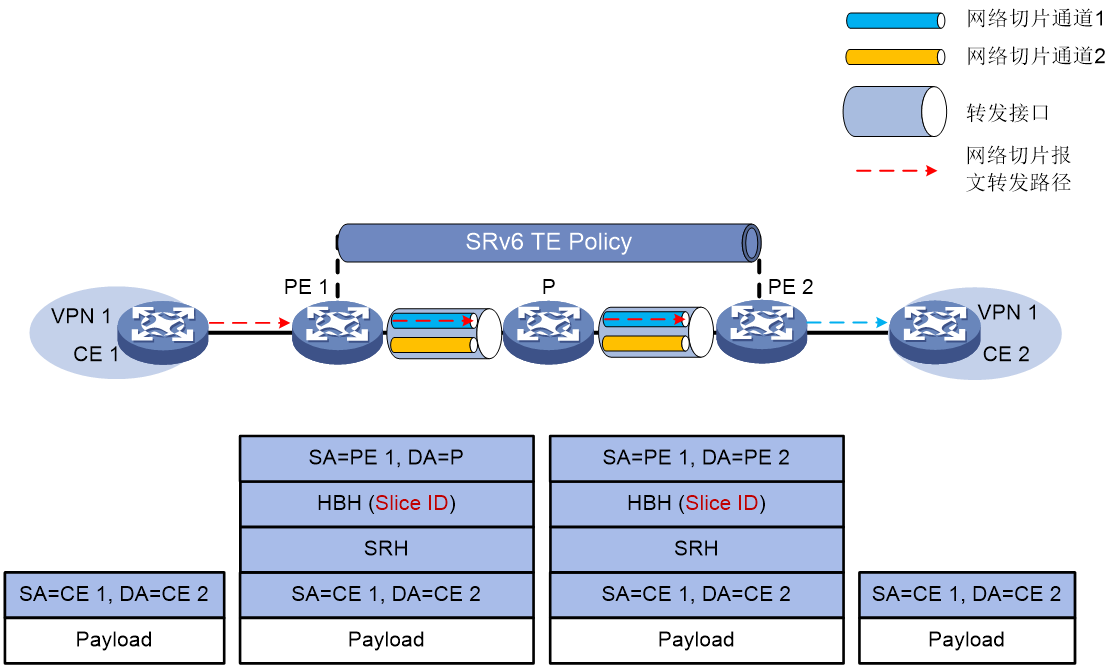
在SRv6网络中存在Slice ID 1和Slice ID 2分别用来表示两个切片网络。PE 1、P和PE 2的转发接口上均存在分别与Slice ID 1和Slice ID 2关联的网络切片通道1和网络切片通道2。VPN 1中两个站点CE 1和CE 2之间的流量使用SRv6 TE Policy承载,SRv6 TE Policy关联了Slice ID 1。CE 1访问CE 2的报文转发过程为:
(1) CE 1向PE 1发送IPv4单播报文。PE 1接收到CE 1发送的报文之后,查找VPN实例路由表,该路由的出接口为SRv6 TE Policy。PE 1为报文封装如下信息:
¡ 封装SRH头,在SRH头中携带SRv6 TE Policy的SID List。
¡ 封装HBH扩展头,在HBH扩展头中携带SRv6 TE Policy关联的Slice ID 1。
¡ 封装IPv6基本报文头。
(2) PE 1将报文转发给P,转发时根据Slice ID信息在出接口上查找与其对应的网络切片通道,并通过该通道转发报文。
(3) 中间P备根据SRH信息转发报文,转发时根据Slice ID在出接口上查找与其对应的网络切片通道,并通过该通道转发报文。
(4) 报文到达尾节点PE 2之后,PE 2使用报文的IPv6目的地址查找Local SID表,匹配到End SID,PE 2将报文SL减1,IPv6的目的地址更新为End.DT4 SID。PE 2根据End.DT4 SID查找Local SID表,执行End.DT4 SID对应的转发动作,即解封装报文去掉IPv6报文头,并根据End.DT4 SID匹配VPN 1,在VPN 1的路由表中,查表转发,将报文发送给CE 2。
图57 基于Slice ID的网络切片方案的报文转发过程
iFIT是一种应用于MPLS(Multiprotocol Label Switching,多协议标签交换)、SR-MPLS(Segment Routing MPLS,MPLS段路由)、SRv6、G-SRv6(Generalized SRv6,通用SRv6)和G-BIER(Generalized BIER,通用位索引显式复制)网络的、测量网络性能指标的测量技术,它直接测量业务报文的真实丢包率和时延等参数,具有部署方便、统计精度高等优点。
![]()
iFIT对G-SRv6和G-BIER网络的支持情况与设备的型号有关,请以设备的实际情况为准。
相较于传统丢包测量技术,iFIT具有以下优势:
· 检测精度高:直接对业务报文进行测量,测量数据可以真实反映网络质量状况。
· 部署简单:中下游设备可以根据iFIT报文生成测量信息。
· 快速定位故障功能:iFIT提供了随流检测功能,可以真正实时地检测用户流的时延,丢包情况。
· 可视化功能:iFIT通过可视化界面展示性能数据,具备快速发现故障点的能力。
· 支持路径自发现功能:iFIT在网络中的入节点对于用户关心的业务流程增加报文头,下游设备可以根据iFIT报文头自动识别该业务流并生成统计测量信息;分析器可以通过该功能感知业务流量在网络中的实时路径。
· 基于硬件实现,对于网络影响较小,可扩展性强。
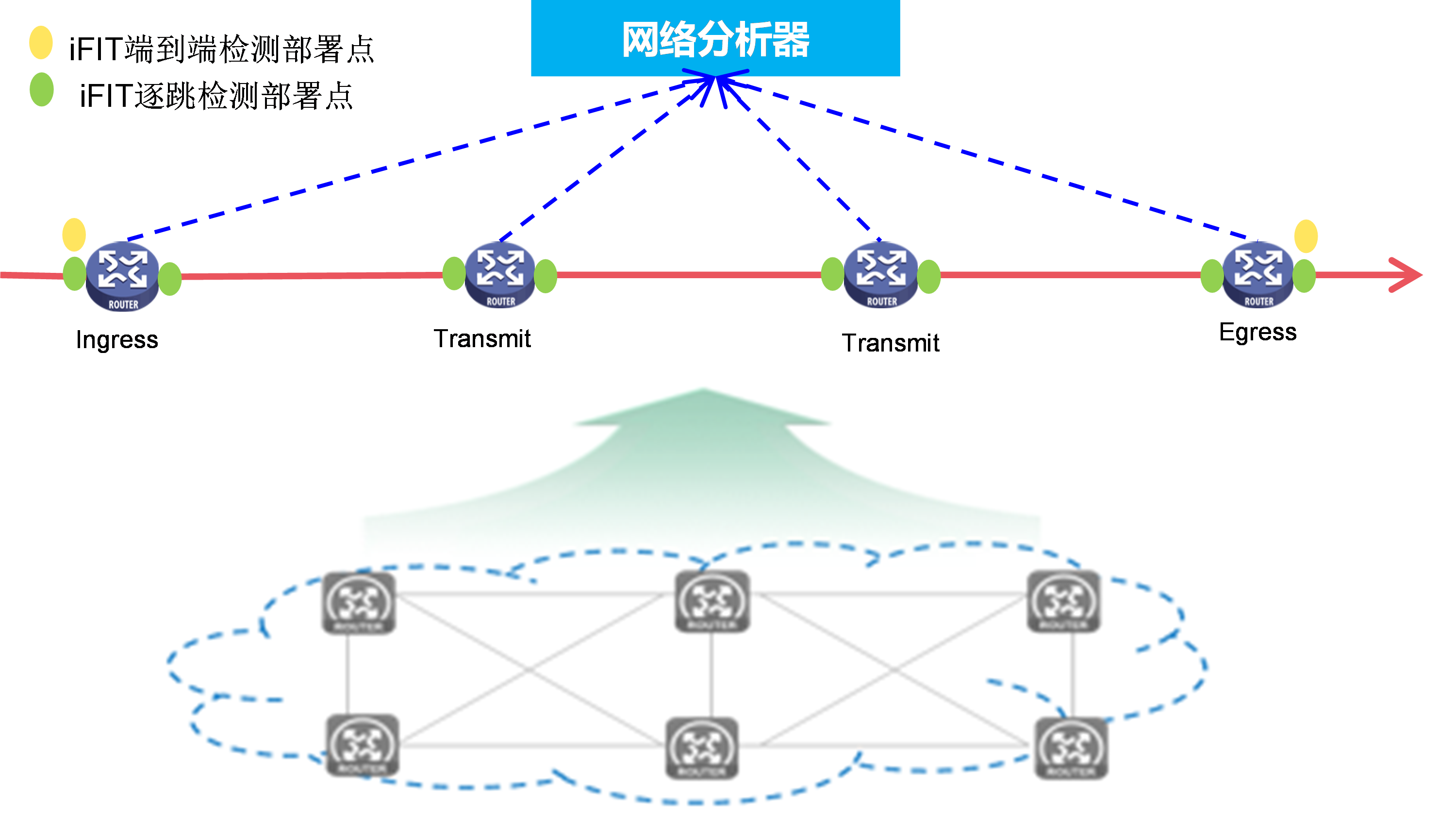
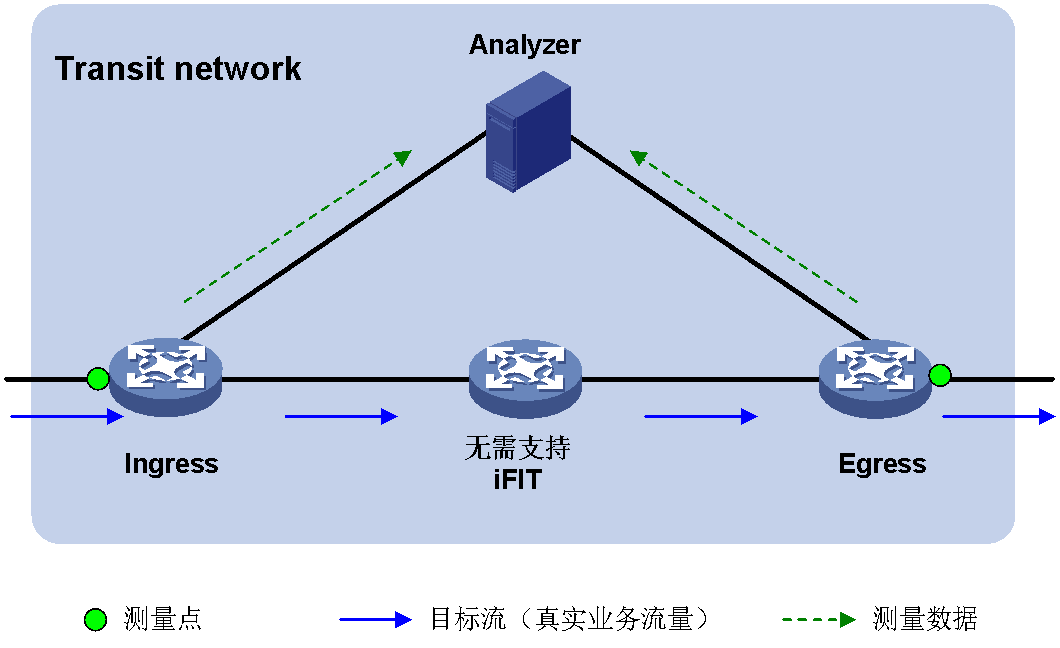
iFIT支持以下两种测量类型:端到端测量和逐点测量,这两种测量类型适用于不同应用场景。
· 端到端测量
当用户希望测量整个网络的丢包和时延性能时,可以选择端到端测量类型。端到端测量会测量流量在进入网络的设备(流量入口)和离开网络的设备(流量出口)之间是否存在丢包以及时延参数。如图58所示,iFIT可用于直接测量流量从Ingress(入节点)到达Egress(出节点)时,是否有丢包、时延,以及丢包率和时延值。
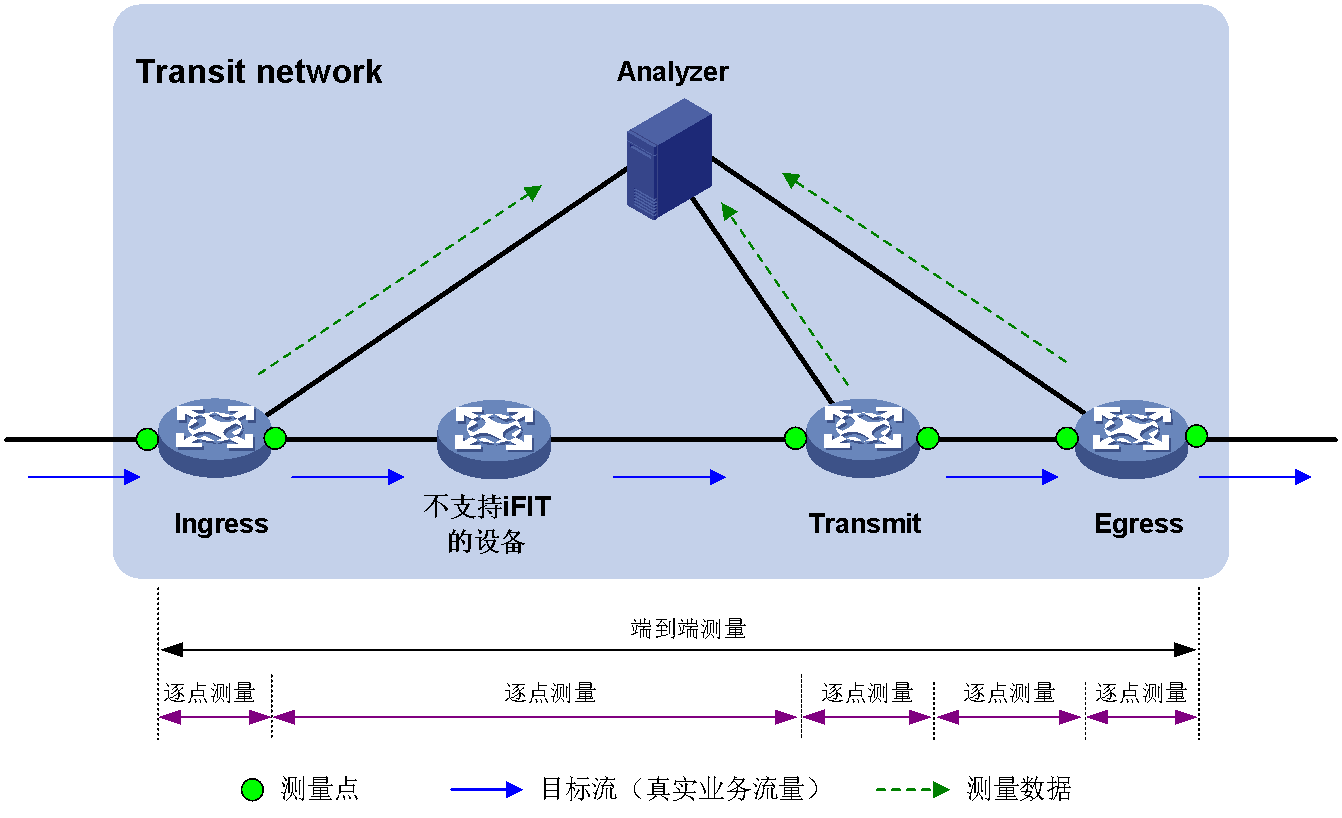
· 逐点测量
当用户希望准确定位每个网络节点的丢包和时延性能时,可以选择逐跳测量类型。当根据测量结果发现端到端统计场景有丢包或者时延不满足业务要求时,可以将端到端之间的网络划分为多个更小的测量区段,测量每两个网元之间是否存在丢包、时延值,进一步定位影响网络性能的网元位置。如图59所示,iFIT可同时测量流量从Ingress到达Egress时,Ingress和Transmit(中间节点)之间、Transmit和Egress之间任意两个接口间是否有丢包、时延,以及丢包率和时延值。
如5.4.3 图58、5.4.3 图59所示,iFIT网络框架中主要涉及三个对象:目标流、目标流穿越的网络(Transit network)和统计系统。
目标流是iFIT统计的目标对象。根据生成方式不同目标流分为静态目标流和动态目标流两种。
· 静态目标流:静态目标流是入节点上手工配置的流匹配规则,在入节点上使用命令行配置完iFIT静态目标流,且开启iFIT测量功能后,入节点会生成一个iFIT静态目标流。设备支持的匹配规则包括五元组(源IP地址/网段、源端口、目的IP地址/网段、目的端口、协议类型)、DSCP、VPN和下一跳参数。
iFIT报文头中包含DeviceID、FlowID、测量周期、测量类型、是否需要测量时延、是否需要测量丢包等重要参数。其中:
¡ DeviceID:设备的标识。在iFIT测量网络中,设备ID用来唯一标识一台设备
¡ FlowID:FlowID由入节点自动生成,会封装到iFIT报文头中传递给中间节点和出节点,用于在iFIT测量网络中与设备标识DeviceID一起唯一的标识一条目标流。
¡ 测量周期:设备按周期进行iFIT测量,从开始一次测量,到收集并上报该次测量数据的时间间隔称为一个测量周期。
¡ 测量类型:表示本次测量是端到端测量还是逐点测量。
· 动态目标流:动态目标流是设备动态学习到的业务流。
¡ 对于入节点,如果设备收到的报文匹配静态目标流的配置,则入节点会生成一个和静态流Flow ID相同的动态目标流。
¡ 对于中间节点和出节点,则通过解析收到的报文,根据报文中携带的iFIT报文头动态学习生成动态目标流。
设备以iFIT报文头中的“DeviceID+FlowID”作为划分动态目标流的依据。如果在指定时间内没有收到相同“DeviceID+FlowID”的报文,则认为该动态目标流已经老化,设备会将该动态目标流删除。
![]()
iFIT对DeviceID的支持情况与设备的型号有关,请以设备的实际情况为准。
· 对于支持DeviceID参数的产品,“DeviceID+FlowID”用于标识一条iFIT流。
· 对于不支持DeviceID参数的产品,用FlowID标识一条iFIT流。
测量点(Detection point):实施iFIT测量的接口。用户可根据测量需求指定测量点。
目标流穿越网络是传输目标流的网络,目标流既不在该网络内产生,也不在该网络内终结。目前支持的目标流穿越网络只能是三层网络。网络内的设备必须路由可达。
统计系统指的是完成iFIT性能统计的所有设备的集合。它包含了以下角色:
· 入节点(Ingress):目标流进入目标流穿越网络的设备,它负责对目标流进行筛选,为目标流添加iFIT报文头,收集目标流的统计数据并上报给Analyzer。
· 中间节点(Transmit):根据报文是否包含iFIT报文头来判断是否为iFIT目标流,对于iFIT目标流,再根据iFIT头中携带的测量类型,决定是否需要收集目标流的统计数据并上报给Analyzer。
· 出节点(Egress):根据报文是否包含iFIT报文头来判断是否为iFIT目标流,对于iFIT目标流,收集目标流的统计数据并上报给Analyzer,去掉报文中的iFIT报文头。
· 分析器(Analyzer):负责收集入节点、中间节点、出节点上送的统计数据并完成数据的汇总和计算。
iFIT以时间同步为基础。在测量开始前,要求所有参与iFIT测量的设备时间已经同步,从而确保各个设备能够基于相同的周期进行报文统计和上报。如果时间不同步,会导致iFIT计算结果不准确。分析器和iFIT设备的时间同步与否不影响计算结果,但为了便于管理和维护,建议分析器和所有iFIT设备的时间均保持同步。iFIT使用PTP(Precision Time Protocol,精确时间协议)协议进行时间同步。关于PTP功能的具体描述和配置请参见“网络管理和监控配置指导”中的“PTP”。
iFIT丢包计算依据报文守恒原理,即每个周期内、从入节点进入的报文总数应该等于出节点发送的报文总数。如果不相等,则说明目标流穿越网络内存在丢包现象。
iFIT时延测量机制原理为:每个测量点会记录目标流中每个报文经过自己的时间戳t0;在下游测量点匹配该报文,并记录该报文经过自己的时间戳t1。最终两个测量点分别将两个时间戳上报给分析器,由分析器计算时延。
iFIT采用gRPC(Google Remote Procedure Call,Google远程过程调用)协议将测量数据从iFIT设备推送给iFIT分析器。
iFIT目前支持gRPC Dial-out模式,iFIT设备作为gRPC客户端,iFIT分析器作为gRPC服务器(在gRPC协议中也称为采集器)。
设备支持按照以下两个周期将测量数据从iFIT设备推送给iFIT分析器,请根据需要选择使用一种即可:
· gRPC订阅周期:如果管理员配置gRPC订阅时配置了采样周期,则不管采样路径是周期采样路径还是事件触发采样路径,设备主动和分析器建立gRPC连接后,均会按照gRPC订阅周期将设备上订阅的iFIT统计数据推送给分析器。
· iFIT测量周期:如果管理员配置gRPC订阅时未配置采样周期,且采样路径是周期采样路径,因为缺少采样周期配置,设备无法将iFIT统计数据推送给分析器;如果管理员配置gRPC订阅时未配置采样周期,且采样路径是事件触发采样路径,设备主动和分析器建立gRPC连接后,设备按照iFIT测量周期定时将设备上订阅的iFIT统计数据推送给分析器。
![]()
· iFIT的周期采样路径为ifit/flowstatistics/flowstatistic。
· iFIT的事件触发采样路径为insuitoam/measurereport(该路径包含了iFIT的测量结果)和insuitoam/flowinfo(该路径包含了iFIT流的信息)。
关于gRPC的详细介绍请参见“Telemetry配置参考”中的“gRPC”。关于iFIT采样路径的详细介绍请参见iFIT的NETCONF API文档。
下面以逐点测量场景为例,说明iFIT的工作机制。(端到端测量的流程与此类似,只是不需要部署中间节点。)
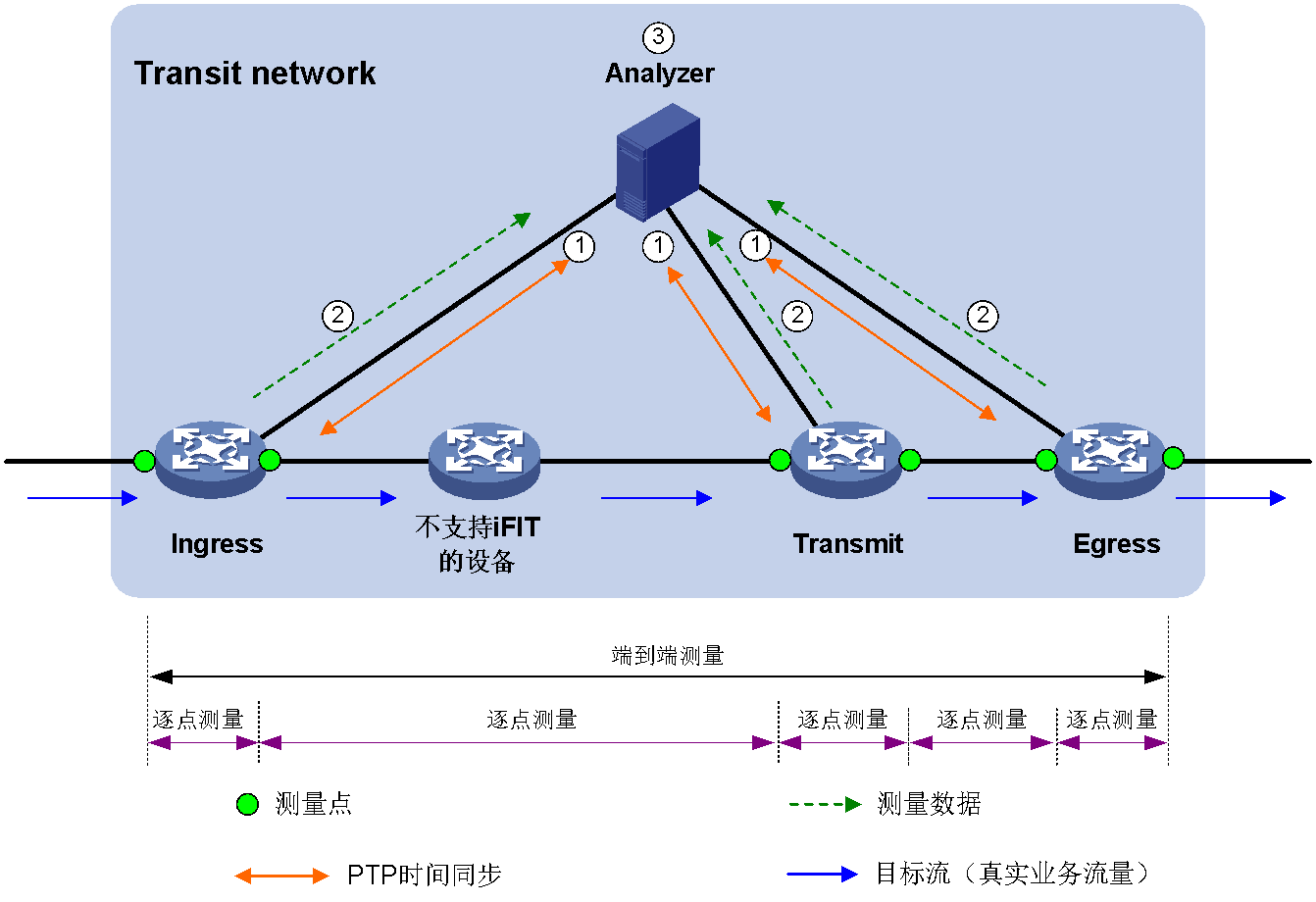
以图60所示组网为例,目标流穿越网络中有四台设备,其中三台支持iFIT,在这三台设备上部署iFIT功能,iFIT的工作流程如下:
(1) Analyzer和所有iFIT设备之间通过PTP协议完成时间的同步。
(2) iFIT设备对目标流报文进行iFIT处理。
a. 在目标流穿越网络的入接口(入节点上用户手工绑定目标流的接口),iFIT会解析流经该接口的报文,按照规则完成目标流的匹配,给目标流报文添加iFIT报文头,统计目标流报文个数,同时按周期将报文计数和时间戳等信息通过gRPC连接上报给分析器。
b. 在目标流穿越网络的传输接口(在目标流穿越网络中支持iFIT的设备上,目标流的流入接口和流出接口),对于包含iFIT报文头的报文,iFIT会统计这些报文的个数,同时按周期将报文计数和时间戳等信息通过gRPC连接上报给分析器。
c. 在目标流穿越网络的出接口(目标流离开目标流穿越网络的接口,可能为出节点上目标流的流入接口,也可能是目标流的流出接口,具体是流入接口还是流出接口不同设备支持情况不同,请以设备实际情况为准),iFIT会解析流经该接口的报文,按照规则完成目标流的匹配,对于包含iFIT报文头的报文,iFIT统计目标流报文个数,同时按周期将报文计数和时间戳等信息通过gRPC连接上报给分析器,去掉目标流报文中的iFIT报文头,继续转发。
(3) 分析器对相同周期、相同实例、相同流量进行丢包分析,计算时延。
图60 iFIT工作机制示意图
传统IP组播和组播VPN技术中,设备需要为每条组播流量分别建立组播分发树,分发树中的每一个节点都需要感知组播业务,并保留组播流状态。例如,公网PIM组播中,需要为每条组播流量建立一个PIM的组播分发树;在NG MVPN中,需要为每条组播流量建立P2MP隧道,也相当于建立一个P2MP组播树。随着组播业务的大规模部署,待维护的组播分发树的数量也急剧增加,组播节点上需要保留大量的组播流状态,当网络发生变化的时候,会导致组播表项收敛缓慢。
同时,单播路由协议、组播路由协议、MPLS协议等多协议在承载网络上并存,增加了承载网络控制平面的复杂度,使得故障收敛速度慢,运维困难,难以向SDN架构网络演进。
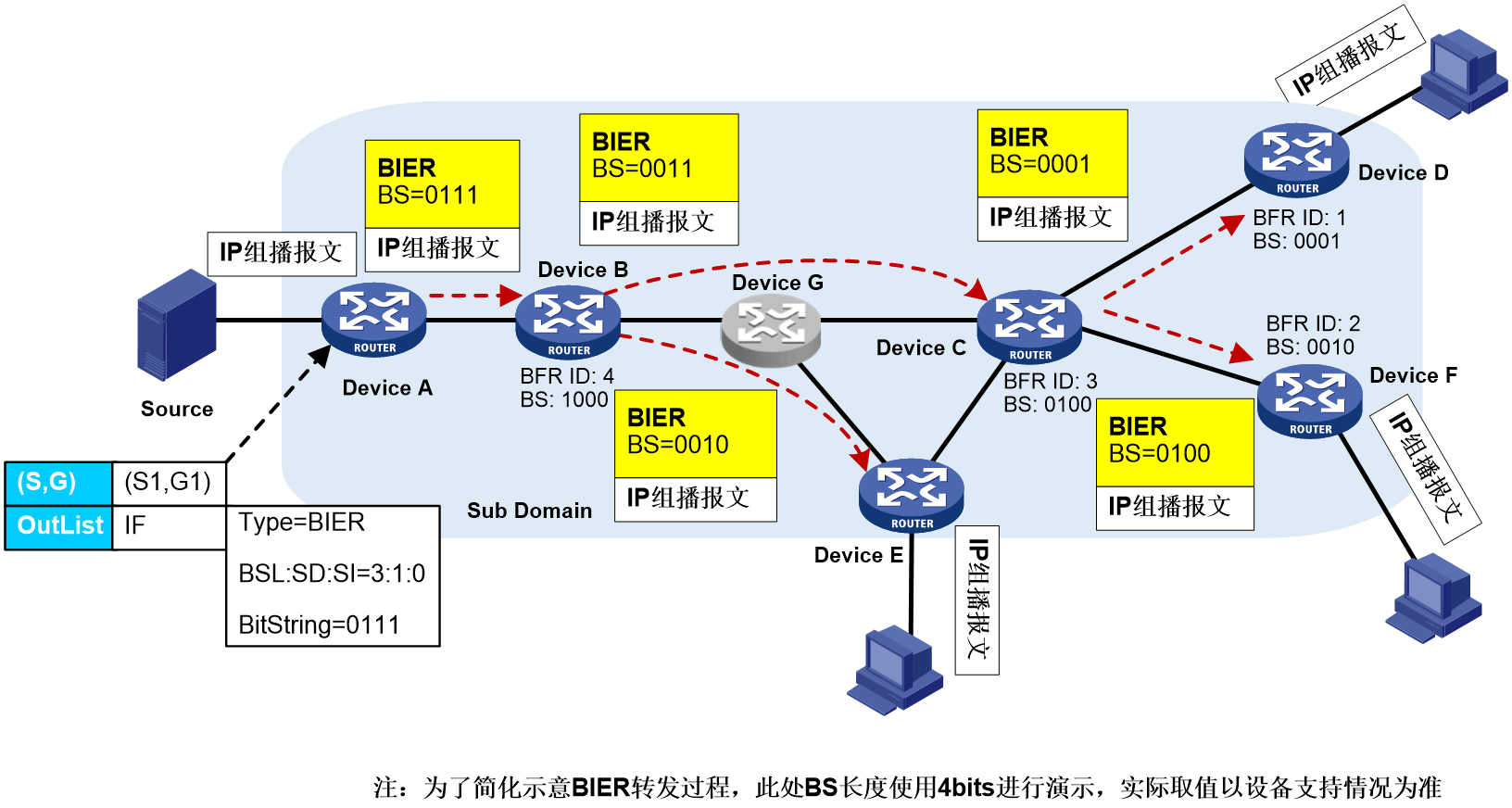
BIER是一种新型的组播转发技术架构,通过将组播报文要到达的目的节点集合以BS(Bit String,位串)的方式封装在报文头部发送,使得网络中间节点无需感知组播业务和维护组播流状态,可以较好地解决传统IP组播技术存在的问题,提供了良好的组播业务扩展性。
在BIER网络中,组播报文的转发依靠BFR(Bit Forwarding Router,位转发路由器)上通过BIER技术建立的BIFT(Bit Index Forwarding Table,位索引转发表),实现组播报文只需根据位串进行复制和转发。
目前,我司支持G-BIER(Generalized BIER,通用位索引显式复制)和BIERv6(Bit Index Explicit Replication IPv6 Encapsulation,IPv6封装的比特索引显式复制)两种封装类型。
BIER具有如下几方面的技术优点:
· 良好的组播业务扩展性
BFR上采用BIER技术建立的BIFT是独立于具体的组播业务的公共转发表,使得网络中间节点无需感知组播业务,不需要维护特定组播业务的组播流状态。公网组播和私网组播报文均可通过BIFT转发,具有良好的组播业务扩展性。
· 简化业务部署和运维
由于网络中间节点不感知组播业务,因此部署组播业务不涉及中间节点,组播业务变化对中间节点没有影响,简化了网络的部署和运维。
· 简化承载网络的控制平面
在承载网络的中间节点上,不需要运行PIM协议,控制平面协议统一为单播路由协议IGP和BGP,简化了承载网络的控制平面协议。
· 利于SDN架构网络演进
部署组播业务不需要操作网络中间节点,只需在入口节点为组播报文添加上指示后续组播复制的BIER封装。BIER封装中携带标识组播出口节点的位串,中间节点根据位串实现组播复制和转发,有利于SDN架构网络的演进。
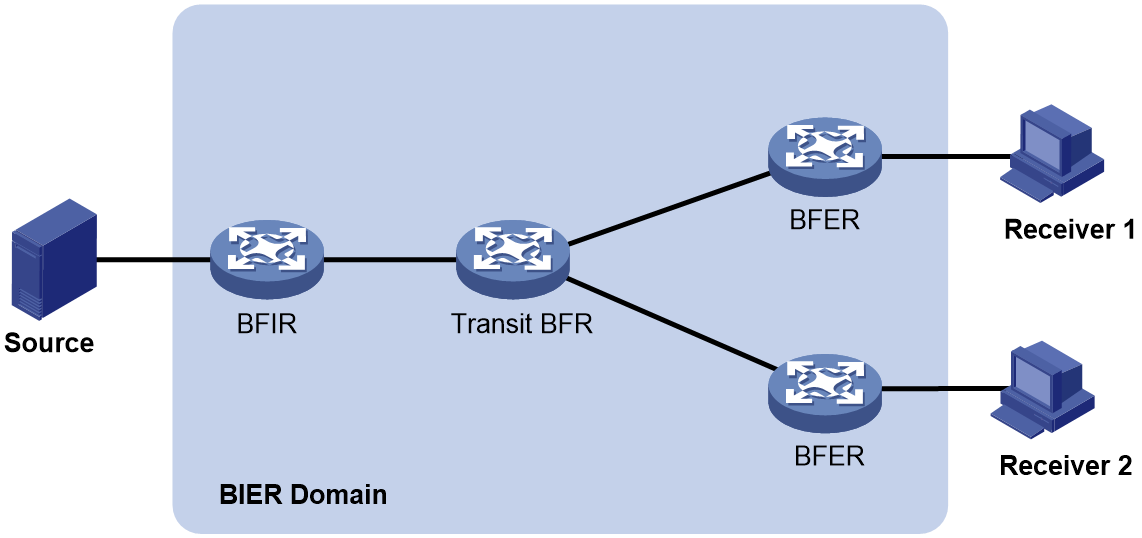
BIER网络的基本元素为支持BIER转发的BFR(Bit Forwarding Router,位转发路由器)。如图61所示,BIER的典型网络模型中包括以下几个部分:
· BFIR(Bit Forwarding Ingress Router,位转发入口路由器):组播数据流量进入BIER域的节点,负责对进入BIER网络的报文进行BIER封装。
· Transit BFR:组播数据流量在BIER域中转发的中间节点,负责对BIER报文进行转发。
· BFER(Bit Forwarding Egress Router,位转发出口路由器):组播数据流量出BIER域的节点,负责对BIER报文进行解封装,并转发给组播接收者。
其中,BFIR和BFER统称为BIER边缘设备。
图61 BIER典型网络模型
· BIER域和BIER子域:在一个路由域或者管理域内所有BFR的集合称为BIER域(Domain)。一个BIER域可以划分为一个或者多个BIER子域(Sub-domain),Sub-domain也可简称为SD。每个BIER子域通过一个唯一的Sub-domain ID来标识。
· BFR ID:用来在一个BIER子域中唯一标识一台BIER边缘设备,Transit BFR无需配置BFR ID。
· BFR prefix:相当于路由协议中的Router ID,用来标识BFR。在同一个BIER子域中,每个BFR必须配置唯一的BFR前缀,且该前缀必须是BIER子域内路由可达的。目前BFR prefix只支持配置为Loopback口的地址。
· BS(Bit String,比特串):BIER封装用一个特定长度的BS来表示BIER报文的目的边缘设备。Bit String从最右边开始,每一个比特位对应一个BFR ID。比特位置1,表示该比特位对应的BFR ID所标识的BIER边缘设备,为组播报文转发的目的边缘设备。
· BSL(Bit String Length,比特串长度):用来表示BIER封装中的比特串长度。
· SI(Set Identifier,集标识):当一个BIER子域内使用的BSL长度不足以表示该子域内配置的BFR ID的最大值时,需要将Bit String分成不同的集合,每个集合通过SI来标识。比如,BIER子域内BFR ID最大值为1024,假如BSL设置为256,就需要将BIER子域分为四个集合,分别为SI 0,SI 1、SI 2和SI 3。
· BIRT(Bit Index Routing Table,位索引路由表):BFR上结合IGP/BGP协议交互的BIER属性信息(Sub-domain ID、BSL、BFR ID)与IGP/BGP路由信息生成的BIER路由表项,用于指导BIER报文的转发。
· F-BM(Forwarding-Bit Mask,转发位串掩码):用来表示BFR往下一跳邻居复制发送组播报文时,通过该邻居能到达的BIER子域边缘节点集合。F-BM是BFR通过将该邻居所能到达的所有BIER子域边缘节点的Bit String进行“或”操作后得到。
· BIFT(Bit Index Forwarding Table,位索引转发表):BIER子域内的组播流量通过查询BIFT来实现逐跳转发。每张BIFT都由三元组(BSL,SD,SI)确定。BIFT是BFR将BIRT表项中经过相同邻居不同表项进行合并生成,每条表项记录了一个下一跳邻居和对应的F-BM。
IETF RFC 8279将BIER网络架构分为Underlay、BIER和Overlay三层。
(1) Underlay层
Underlay层为传统IP路由层,通过IGP协议(目前仅支持IS-IS)的扩展TLV属性携带BFR的BIER属性信息在BIER子域内进行泛洪。BFR根据IGP算法生成到本子域内其它BFR前缀的路由,也就是到每个BFR的路由,从而建立BIER子域内节点之间的邻居关系以及节点之间的最佳转发路径。
(2) BIER层
BIER层作为BIER转发的核心层,在控制平面对BIER转发所需的IGP协议进行了扩展,用于生成指导组播报文在BIER域内完成转发的BIFT。BIFT生成过程如下:
a. BFR通过IGP协议将BIER层配置的BIER信息进行通告。
b. BFR基于IGP协议通告的BIER信息,在BFR之间的最佳转发路径上生成BIFT。
在转发平面,当封装有BIER头的组播报文在BIER层进行转发时,BFR根据BIER头中的信息查找BIFT表项完成报文复制转发。
(3) Overlay层
Overlay层在控制平面主要负责组播业务控制面信息交互,比如BFIR和BFER之间用户组播的加入和离开信息,建立组播流与BFER对应关系的组播转发表项。
在转发平面,当组播报文到达BFIR时确定目的BFER集合,并完成该组播报文对应的BIER头的封装;当携带有BIER头的组播报文到达BFER节点时,解封装BIER头并完成后续的组播报文转发。
RFC 8279中对BIER定义了多种封装类型,不同的封装类型报文格式不相同。目前,我司支持G-BIER和BIERv6封装类型。
· G-BIER(Generalized BIER,通用位索引显式复制)为中国移动携手新华三、华为、中兴等厂商提出的一种通用BIER封装方案,它根据IPv6网络的特点对RFC定义的标准的BIER头进行适配性修改,与IPv6实现了更好的融合。
· BIERv6(Bit Index Explicit Replication IPv6 Encapsulation,IPv6封装的比特索引显式复制)是基于Native IPv6的全新组播方案,BIERv6结合了IPv6和BIER的优势,可以无缝融入SRv6网络,简化了协议复杂度。将BIER承载报文的封装类型配置为BIERv6时,需要BIER子域内的所有的BFR均支持SRv6。
对G-BIER报文的封装是通过在组播数据报文前面添加新的IPv6基本头和G-BIER头实现的。如图62所示,IPv6基本头中Next Header取值为60,表明下一个报文头为DOH(Destination Options Header,目的选项头)。
对于G-BIER报文,IPv6基本头中有如下约定:
· Source Address:源地址需要配置为BFIR的组播服务源地址,该源地址由BFIR的前缀地址和组播服务ID值共同生成。BFIR的前缀地址用来标识BFIR的网络位置,组播服务ID用来标识不同的MVPN实例。组播报文在转发过程中,该源地址保持不变。
· Destination Address:目的地址需要配置为专门用于BIER转发的MPRA(Multicast Policy Reserved Address,组播策略保留地址),该地址要求在子域内路由可达。当BFR收到IPv6报文中的目的地址为本地配置MPRA,则表示需要对该报文进行G-BIER转发。
图62 G-BIER的报文封装示意图
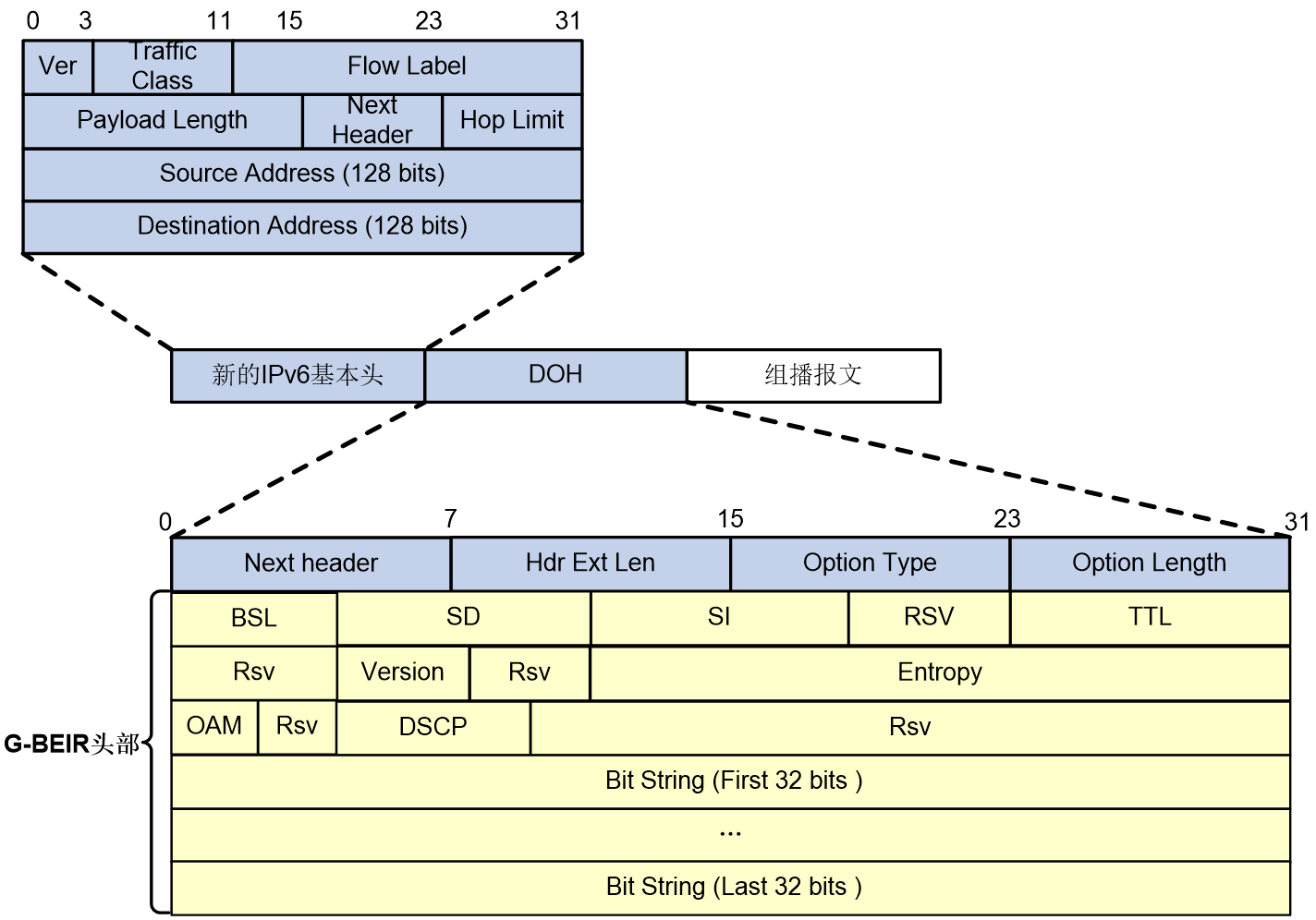
G-BIER报文中的BIER头主要包含以下几个部分:
· Next Header:8bits,用来标识下一个报文头的类型。
· Hdr Ext Len:8bits,表示IPv6扩展头长度。
· Option Type:8bits,选项类型为G-BIER。
· Option Length:8bits,选项长度。
· BSL:4bits,取值用1~7来代表不同比特串长度,取值与比特串长度的对应关系如下:
¡ 1:表示比特串长度为64bits。
¡ 2:表示比特串长度为128bits。
¡ 3:表示比特串长度为256bits。
¡ 4:表示比特串长度为512bits。
¡ 5:表示比特串长度为1024bits。
¡ 6:表示比特串长度为2048bits。
¡ 7:表示比特串长度为4096bits。
· SD:8bits,BIER子域ID。
· SI:8bits,集标识。
· Rsv:保留字段。
· TTL:8bits,和IP报文中的TTL意义相同,可以用来防止环路。
· Version:4bits,版本号,目前只支持0。
· Entropy:20bits,用来在存在等价路径时,进行路径的选择。拥有相同Bit String和Entropy值的报文,选择同一条路径。
· OAM:4bits,缺省值为0,可用于OAM功能。
· DSCP:7bits,报文自身的优先等级,决定报文传输的优先程度。
· Bit String:位串。
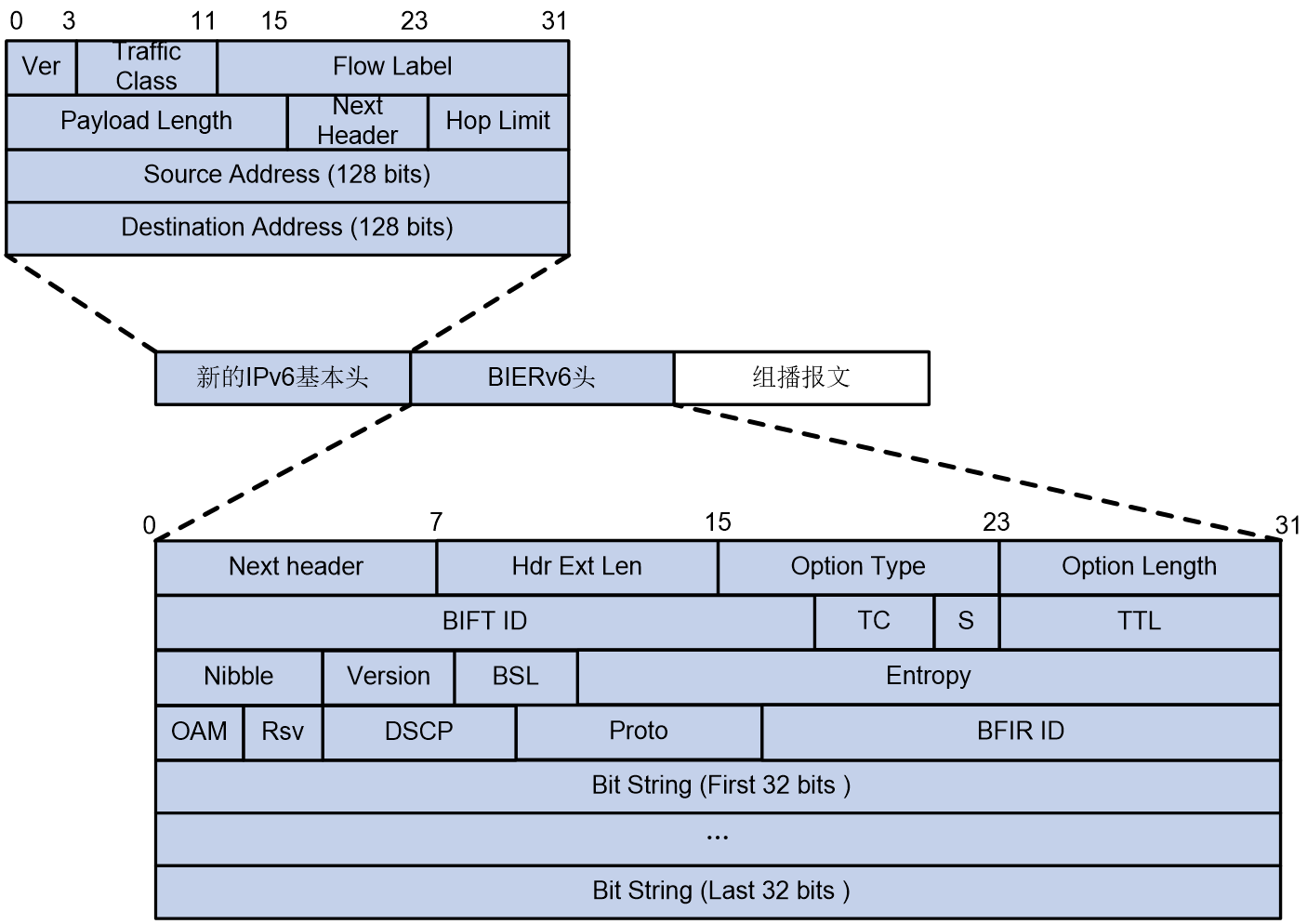
对BIERv6报文的封装是通过在组播数据报文前面添加新的IPv6基本头和BIERv6头实现的。如图63所示,IPv6基本头中Next Header取值为60,表明下一个报文头为DOH(Destination Options Header,目的选项头)。
对于BIERv6报文,IPv6基本头中有如下约定:
· Source Address:源地址需要配置为BIERv6隧道的源地址,在组播报文在公网中转发时,该源地址保持不变。有关BIERv6隧道源地址的详细介绍,请参见“IP组播配置指导”中的“组播VPN”。
· Destination Address:目的地址需要配置为专门用于BIER转发的End.BIER SID,该地址要求在子域内路由可达,可通过end-bier locator命令进行配置。
BIERv6头主要包含以下几个部分:
· Next Header:8bits,用来标识下一个报文头的类型。
· Hdr Ext Len:8bits,表示IPv6扩展头长度。
· Option Type:8bits,选项类型为BIERv6。
· Option Length:8bits,表示BIERv6报文头长度。
· BIFT-ID:20bits,位索引转发表ID,用来唯一标识一张BIFT。
· TC:3bits,Traffic Class,流量等级,用于QoS。。
· S:1bits,可视为保留字段。
· TTL:8bits,表示报文经过BIERv6转发处理的跳数。每经过一个BIERv6转发节点后,TTL值减1。当TTL为0时,报文被丢弃。
· Nibble:4bits,保留字段,目前只支持0。
· Version:4bits,BIERv6报文版本号,目前只支持0。
· BSL:4bits,取值用1~7来代表不同比特串长度,取值与比特串长度的对应关系如下:
¡ 1:表示比特串长度为64bits。
¡ 2:表示比特串长度为128bits。
¡ 3:表示比特串长度为256bits。
¡ 4:表示比特串长度为512bits。
¡ 5:表示比特串长度为1024bits。
¡ 6:表示比特串长度为2048bits。
¡ 7:表示比特串长度为4096bits。
· Entropy:20bits,用来在存在等价路径时,进行路径的选择。拥有相同Bit String和Entropy值的报文,选择同一条路径。
· OAM:2bits,缺省为0,可用于OAM功能。
· Rsv:2bits,保留字段,缺省为0。
· DSCP:6bits,报文自身的优先等级,决定报文传输的优先程度。
· Proto:6bits,下一层协议标识,用于标识BIERv6报文头后面的Payload类型。
· BFIR ID:16bits,BFIR的BFR ID值。
图63 BIERv6的报文封装示意图
在BFR上配置的BIER信息(SD、BFR prefix、BFR ID等),通过IGP协议在BIER域内泛洪。IGP根据邻居泛洪的BIER信息计算BIER最短路径树(以BFIR为根,Transit BFR和BFER为叶子)。BFR根据BIER最短路径树,生成BIRT,最终进一步生成用于指导BIER转发的BIFT。
如图64所示,BIER域中包含支持BIER和不支持BIER的节点(Device G)。对于不支持BIER的节点,会将其所有的子节点作为叶子节点加入到BIER最短路径树,如果子节点不支持BIER,则继续往下迭代到支持BIER的子节点。比如,Device G不支持BIER,Device G会将子节点Device C和Device E的BIER信息传递给Device B,在Device B上生成下一跳邻居为非直连邻居Device C和Device E的BIFT表项信息。
图64 BIER控制平面BIFT
组播报文到达BFIR,BFIR查找组播转发表得到该组播表项对应的BIFT-ID和BS,BS即组播报文穿越BIER域后到达的全部BFER集合。BFIR根据BIFT-ID匹配到指定BIFT,并根据报文头中携带的Bit String与BIFT表项匹配计算后复制转发。BIER报文到达BFER节点后解封成组播报文,根据组播地址查找组播转发表进行转发。
当BIER转发过程中需要经过非BIER节点,即BFR的下一跳邻居为非直连邻居时,可以通过特定的技术来穿越非BIER节点。特定的技术取决于BIER封装的外层封装(比如,MPLS封装依靠LSP穿过非BIER节点,IPv6封装可以按普通IPv6单播路由到非直连BIER邻居)。
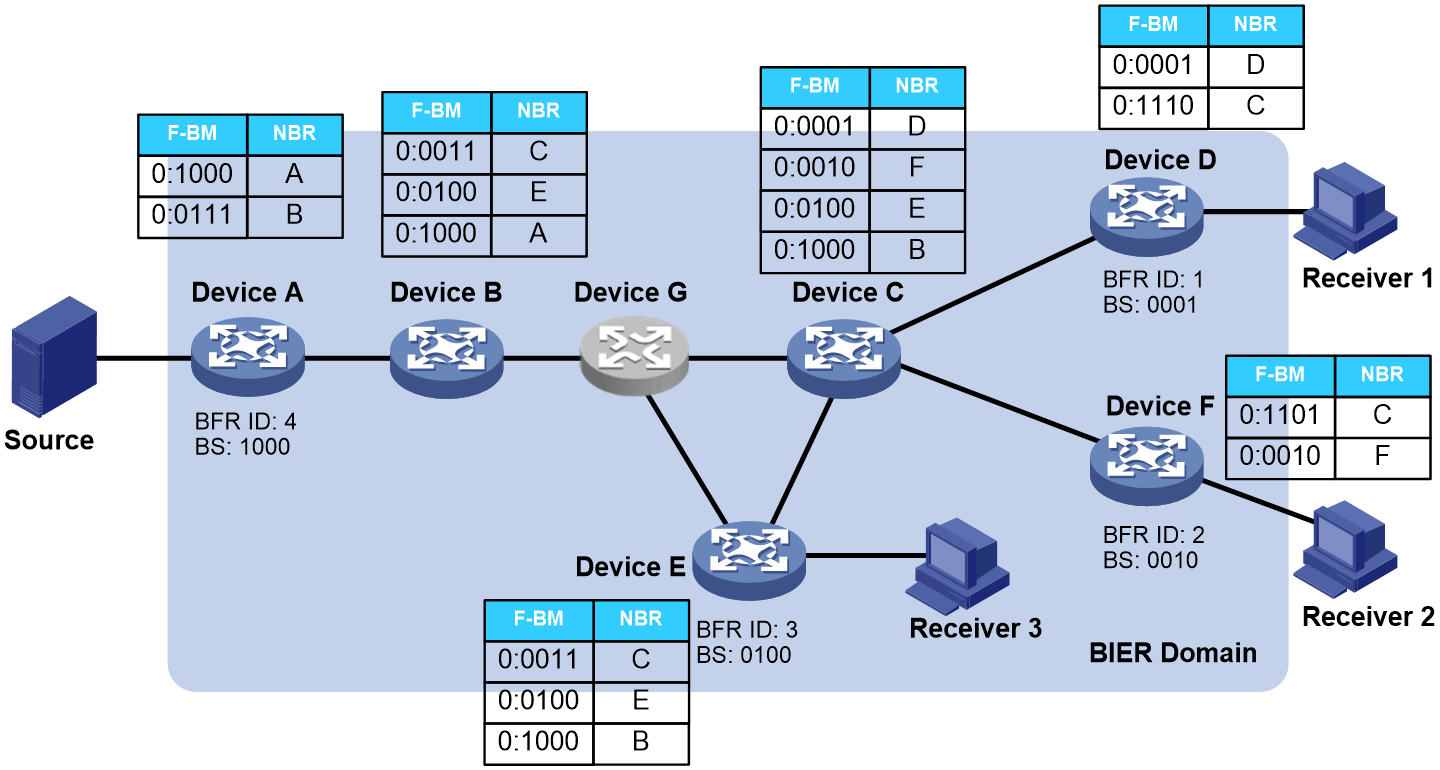
下面以具体的示例来说明BIER转发过程。如图65所示,BIER子域中的每台设备都根据IGP协议计算生成了BIFT。Device D和Device E的下游存在某个组播组的接收者,Device A作为BFIR通过BGP MVPN路由收集到Device D和Device E上与Device A处于相同BIER子域的MVPN信息。当Device A收到发往该组播组的组播报文时,BIER转发过程如下:
(1) Device A收到IP组播报文后,查找组播转发表项,得到该组播表项对应的BIFT-ID和BS,根据BIFT-ID找到对应的BIFT表,将BS与BIFT表中每行表项F-BM进行“位与”操作,复制组播报文并按照BIER报文格式封装(封装的BS为“位与”计算后得到的值),发送给下一跳邻居Device B。
(2) Device B收到BIER报文后,根据BIER头中的BIFT-ID和BS,执行与步骤(1)相同的步骤,发现下一跳邻居为Device C和Device E,需要经过非BIER的节点Device G。此时,可以通过特定的技术穿越非BIER节点,复制组播报文并按照BIER报文格式封装后,发给Device C和Device E。
(3) Device C收到BIER报文后,执行与步骤(1)相同的操作,将组播报文复制一份,并按照BIER报文格式封装后,发给Device D和Device F。
(4) Device D、Device E和Device F收到BIER报文后,发现只有本节点对应的F-BM与上游发送的BIER报文中的BS进行“位与”操作后不为0,表明本节点为BFER,需要结束BIER转发。此时,Device D、Device E和Device F分别从BIER头部解封装出组播报文后,根据组播路由表项继续转发给下游接收者。
图65 BIER报文转发过程示意图
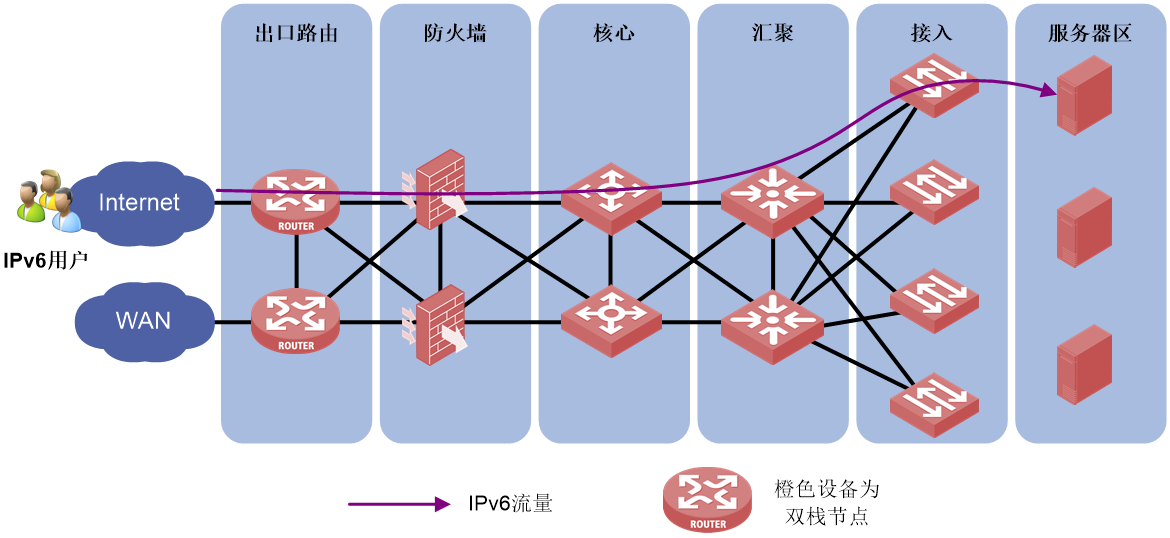
IPv6升级改造方案包括如下几种:
· 新建IPv6网络
· 部分设备支持双栈
· 网络边界进行地址翻译
新建IPv6网络方案是指按照现有的网络建设模式组建全新的IPv6网络,网络中的设备均支持IPv4和IPv6双栈,该网络仅用来处理IPv6流量。全新的IPv6网络中可以部署新业务,以实现业务创新。
图66 新建IPv6网络示意图
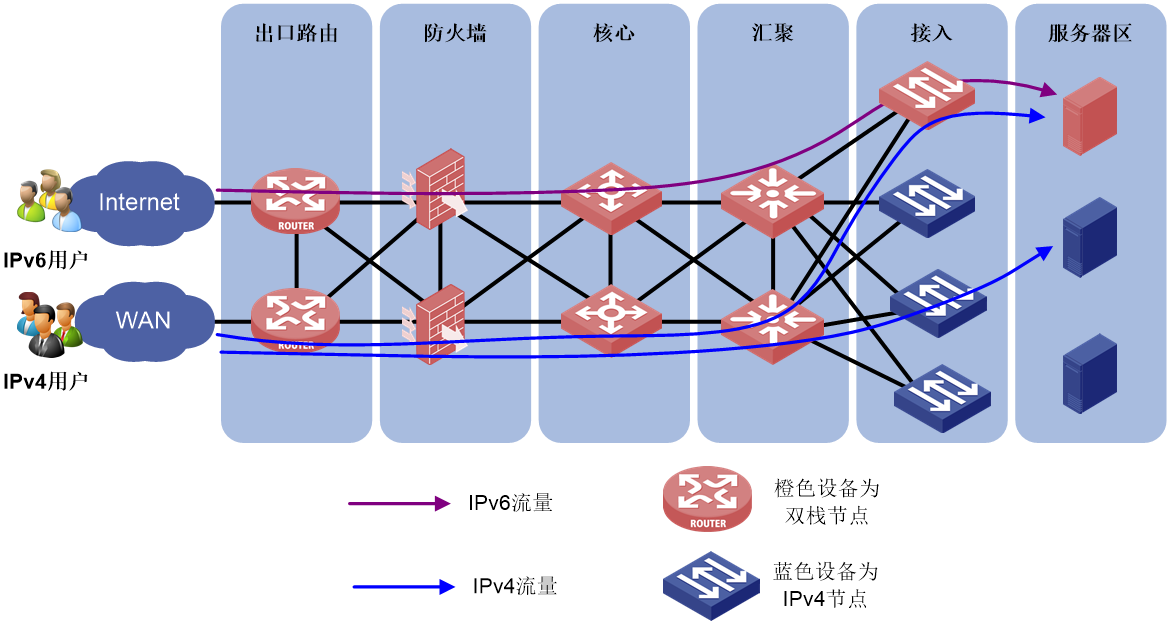
新建IPv6网络方案是指仅网络出口、防火墙、核心设备、部分汇聚/接入设备支持双栈,IPv6用户通过这些双栈节点进行通信。
图67 部分设备支持双栈示意图
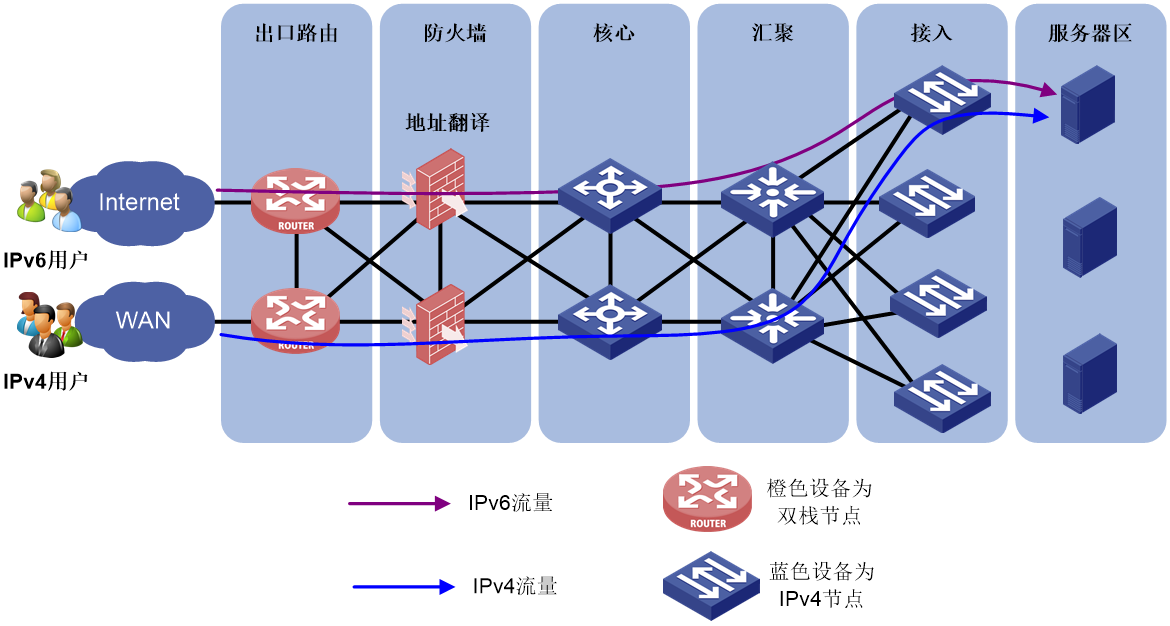
网络边界进行地址翻译方案是指在位于IPv4与IPv6网络边界的防火墙上开启AFT等地址转换协议,对IPv4和IPv6地址进行相互转换,从而实现IPv6用户访问IPv4网络。
图68 网络边界进行地址翻译示意图
IPv6网络的三种升级改造方案对比如所示。
表11 升级改造方案对比表
|
升级改造方案 |
新建IPv6网络 |
部分设备支持双栈 |
网络边界进行地址翻译 |
|
改造成本 |
高 |
中 |
低 |
|
改造难度 |
低 |
高 |
低 |
|
改造工作量 |
中 |
中 |
低 |
|
改造风险 |
低 |
高 |
中 |
|
对原有业务影响 |
无影响,IPv6业务完全重新部署 |
有影响,IPv4和IPv6应用复用双栈网络 |
无影响,原有IPv4业务不需要进行地址转换 |
|
单点设备压力 |
低 IPv4和IPv6两张网络,由不同的设备处理IPv4和IPv6流量 |
中 网络、防火墙等各节点需部署双栈协议,设备资源表项共享 |
高 地址转换的节点成为网络瓶颈 |
|
运维复杂度 |
IPv4/IPv6运维界面分离,运维简单 |
IPv4/IPv6运维界面混合,运维复杂 |
延续IPv4运维方式,运维简单 |
|
适用场景 |
业务系统重要、架构复杂,改造难度大的网络(如金融网银业务等) 具有业务创新需求的网络 |
结构清晰、简单的网络 |
资金预算紧张,或希望尽量减少IPv6对现网冲击的网络 |
园区网全面IPv6化的典型部署方案如图69所示。具体部署方法为:
· 在互联网出口区:
¡ 防火墙、IPS、LB、应用控制、流量分析等设备全面支持IPv6。
¡ 全面支持AFT等地址转换协议。
· 在校园云数据中心:
¡ Underlay、Overlay网络支持IPv6。
¡ 虚拟化、云平台全面支持IPv6。
¡ 部署AFT等地址转换协议。
· 在管理控制服务器区:
¡ 安全态势感知支持IPv6。
¡ 认证授权、网管服务器支持IPv6。
· 在有线、无线园区网:
¡ 支持IPv6地址分配,IPv6路由协议。
¡ 支持IPv6准入(BRAS或ADCampus)。
¡ 支持有线、无线接入SAVA和域内SAVA,防止源地址假冒攻击。
· 在DMZ区域:设置DNS64、对外IPv6化网站群等。
图69 园区网全面IPv6化典型组网
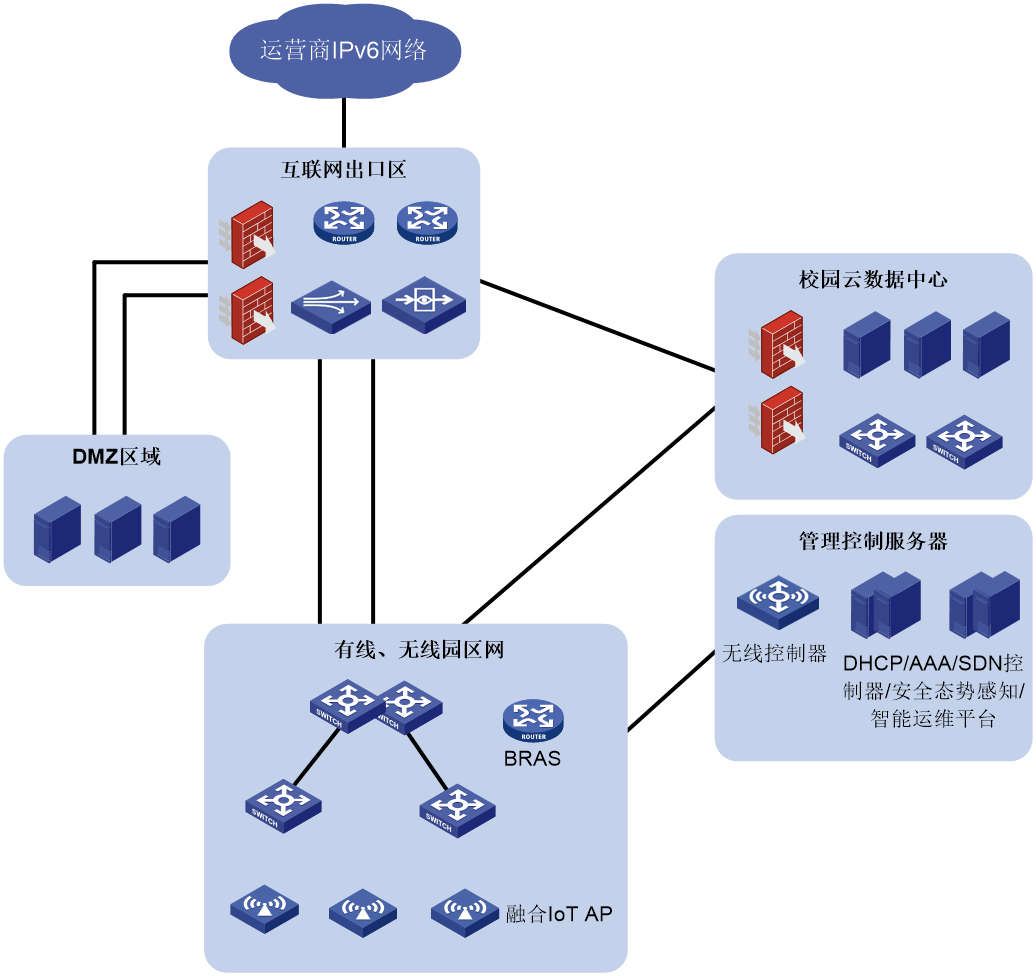
如图70所示,金融网络由以下几部分组成:
· 互联网接入区:通过ISP的Internet线路完成用户的网络接入功能,该区域部署广域网接入路由器,实现多ISP的多条Internet线路接入。
· DMZ(Demilitarized Zone,隔离区)区:为用户提供Web服务的服务器位于DMZ区。通过防火墙和IPS,实现互联网与DMZ区隔离;DMZ区内部署路由器和交换机,实现本区域内所有设备的互联互通;通过负载均衡设备,优化业务响应速度并保证Web业务高可用性。
· 核心交换区:连接DMZ区和互联网业务后台区、数据中心内网服务器区。
· 互联网业务后台区:主要提供门户、网银、互联网金融业务的应用处理。
· 数据中心内网服务器区:包含多个业务区,主要为APP服务器或DB提供数据服务。
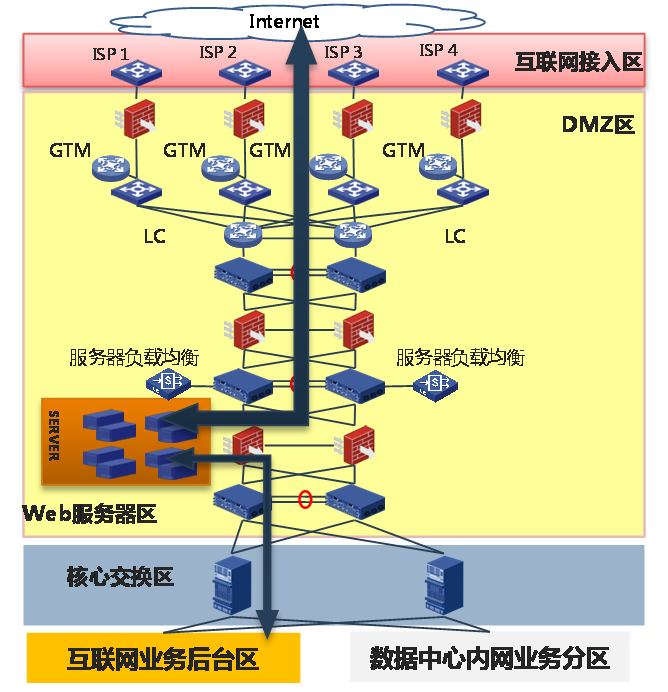
可以通过以下几种方案实现金融网络从IPv4到IPv6网络的升级:
· 完全新建纯IPv6区:新建纯IPv6的互联网接入区和DMZ区。互联网接入区和DMZ区通过IPv6对外提供Web服务,通过IPv4和后端业务后台区、内网业务区数据拉通
图71 完全新建纯IPv6区
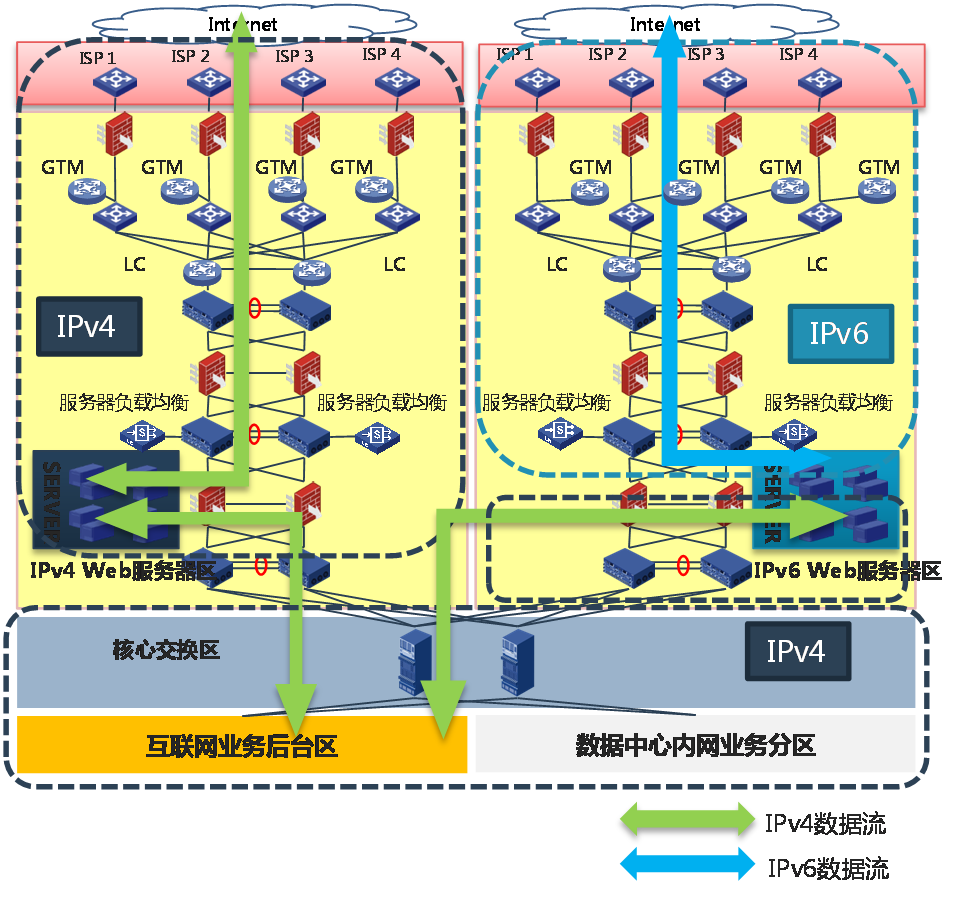
· 新建IPv6 Web服务器集群:改造互联网接入区和DMZ区支持双栈,原有IPv4 Web服务器集群和新建的IPv6 Web服务器集群共用双栈网络。
图72 新建IPv6 Web服务器集群
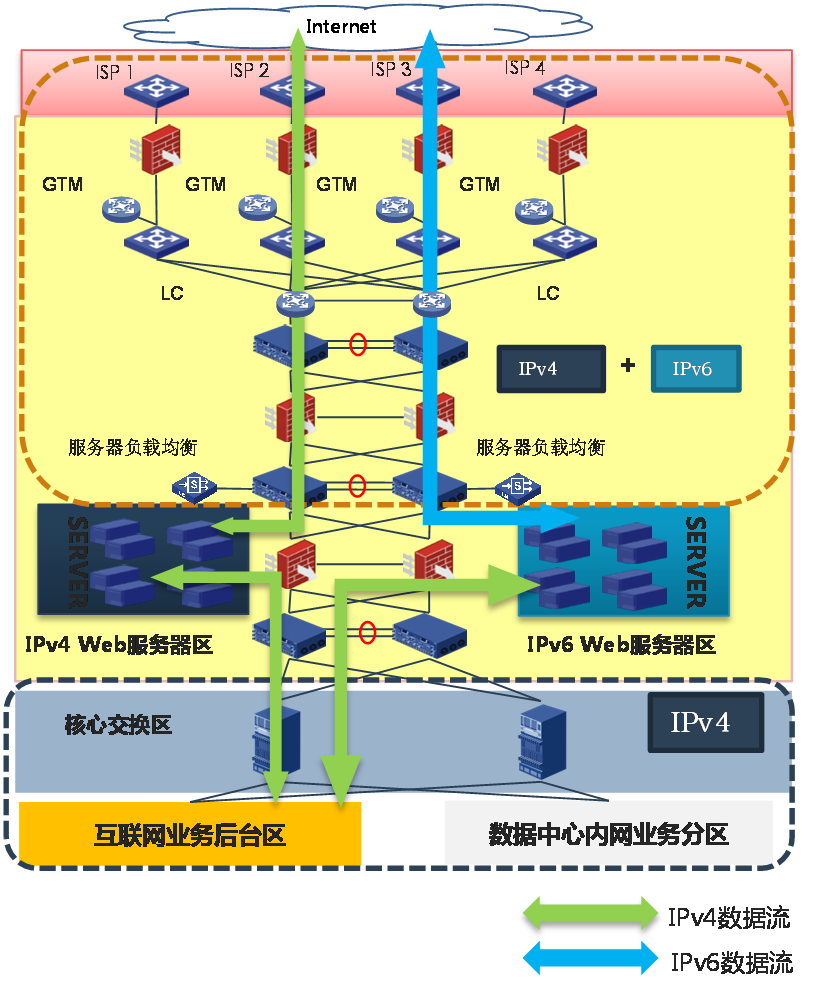
· 原Web服务器集群网络升级为双栈网络:改造互联网接入区、DMZ区和Web服务器集群网络支持双栈。
图73 原Web服务器集群网络升级为双栈网络
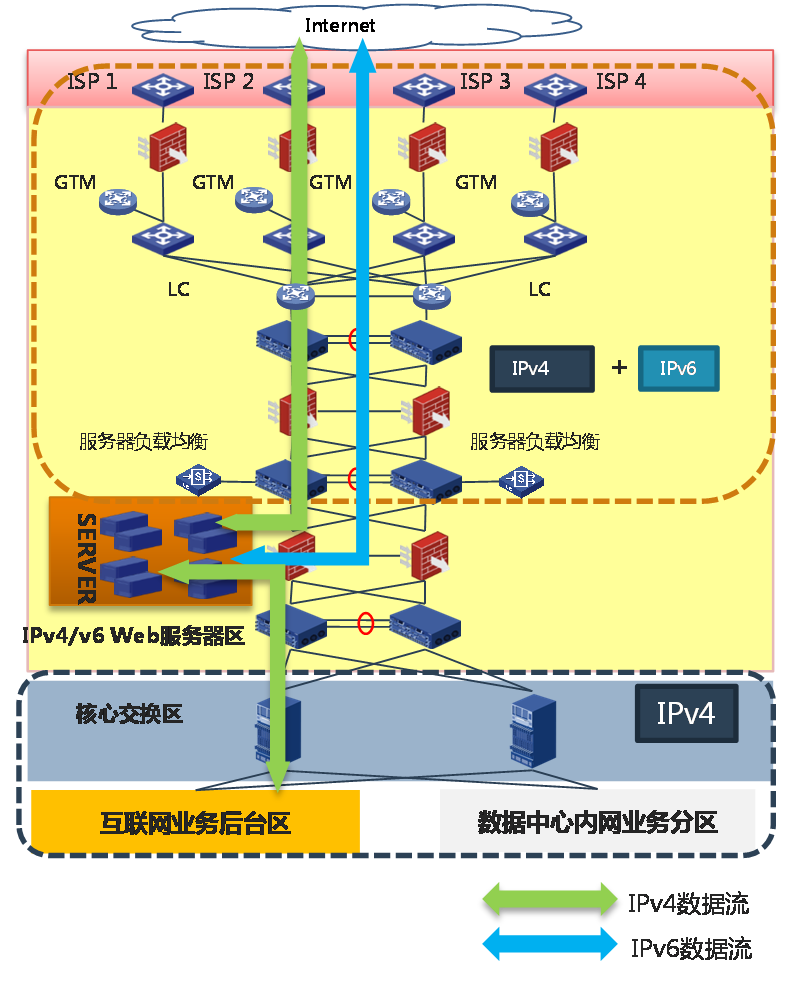
电子政务外网中SRv6的部署方案如图74所示。
· 访问互联网的上网流量通过EVPN over SRv6承载,为上网用户分配相应VPN权限,并通过SRv6隧道进行流量承载。
· 公共业务流量可以使用公网地址,直接通过SRv6进行承载。
· 专网流量进行相应EVPN的划分,保证专网专用,业务逻辑隔离。
· 所有路径都可以由SDN控制器进行动态调整,保证资源利用率最优。
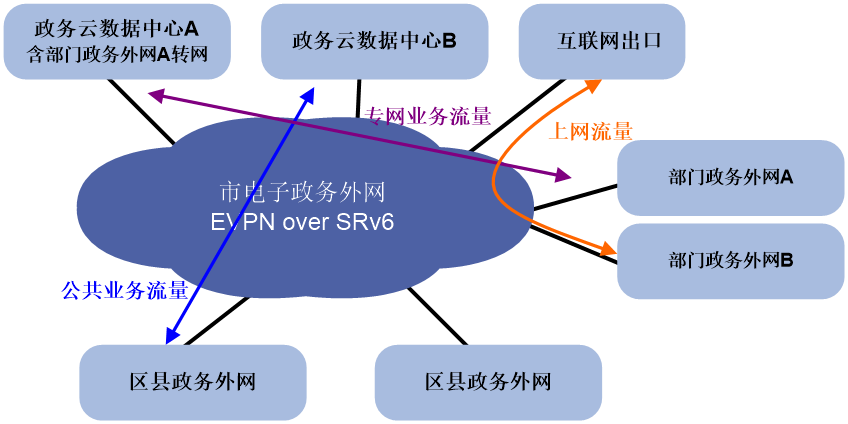
电子政务外网中网络切片的部署方案如图75所示。
· 综合运用多种网络切片技术,将骨干网带宽细化,形成多通道。
· 根据不同的业务需求(时延/抖动/丢包等),通过控制器进行不同策略的下发,实现对通道的多样性利用。
· 可以根据需求为不同专网(例如应急指挥网络、视频会议网络、公文下载网络等)分配不同的带宽,保障在同一拓扑中,一个专网的流量不会因为另一个专网流量的拥塞而丢包。
· 可根据客户的业务需求灵活编排SRv6转发路径,提升网络智能性。
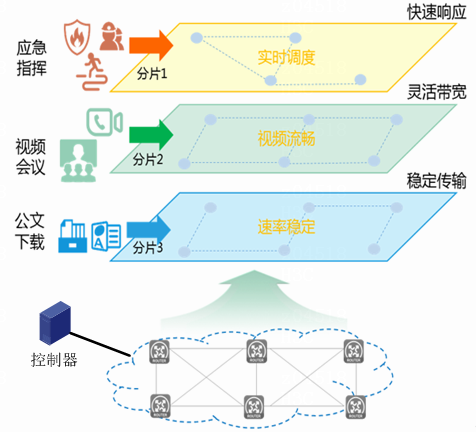
电子政务外网中可视化的部署方案如图76所示。通过基于iFIT和Telemetry技术的可视化方案可以实现:
· 质量可视,规划支撑:周期性的数据收集,形成现网报表数据,为扩容及后续规划等提供数据支撑。
· 随需而动,智能运维:根据现网业务状态,实现网络路径等智能调优,保障关键业务质量。
· 精准定位、快速排障:业务出现问题时,通过网络分析器上的图形展示可快速定界和解决问题。
![]()
Telemetry的详细介绍,请参见《Telemetry技术白皮书》。